
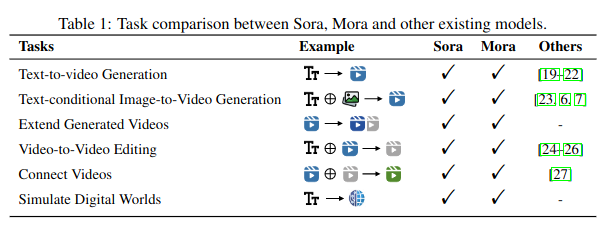
Introduction
Generative AI, in its essence, is like a wizard’s cauldron, brewing up images, text, and now videos from a set of ingredients known as data. The magic lies in its ability to learn from this data and generate new, previously unseen content strikingly similar to the real thing. Image generation models like DALL-E have already amazed us, turning prompts like “an astronaut riding a horse on Mars” into striking visuals. Yet, the frontier of video generation remained a tough nut to crack—until recently. Sora has got its competitor with extanding and replicating abilities. Mora is a collaborative multi-agent framework for versatile video generation, aiming to enhance and replicate OpenAI’s Sora capabilities.
Video generation takes the challenge up a notch. It’s not just about creating a single frame but weaving together a sequence where each moment flows into the next, creating a story that moves and breathes. The complexity here is immense. Videos must maintain consistency, not just within frames but across time, embodying the dynamics of a world in motion. It’s like directing a film where the scriptwriter, director, and entire cast are all rolled into one AI model.

Bridging the Gap: Mora as an Alternative to Sora’s Closed-Source Limitations
Introduced by OpenAI, Sora represents a significant advancement in video generation technology, capable of turning simple text descriptions into minute-long videos that capture the essence of life and motion. Imagine the ability to create a vivid scene of a bustling city street at dawn with just a few words, showcasing the transformative power of this technology. However, the vast potential of Sora remains somewhat shrouded in mystery, as its capabilities, while impressive, are not openly accessible for exploration and development by the wider academic and research communities that flourish on transparency and the free exchange of ideas.
In contrast, Mora emerges as a beacon of hope and innovation, seeking to democratize the advancements made by Sora. Unlike its forerunner, Mora is not merely another tool in the arsenal of video generation technologies; it is a clarion call to researchers and creators alike to push the envelope of what is possible. By embracing an open-source, multi-agent framework, Mora decentralizes the video creation process, akin to assembling a diverse team of specialists, each contributing their unique skills towards crafting a masterpiece. This approach not only broadens the scope for flexibility and innovation but also cultivates a community ethos where advancements and insights are shared openly. Although Mora is on a journey to meet the lofty benchmarks established by Sora, its foundational philosophy promises a future where the magic of turning text into breathtaking video narratives is accessible to a broader audience. Through Mora, the domain of generative AI and video generation signals a future marked by collaborative discovery and the pursuit of the extraordinary, shared amongst a united community.
Text-to-Video Generation: Crafting Stories from Words
Imagine crafting vivid scenes using nothing but words. This is the essence of text-to-video generation, a rapidly evolving field that transforms textual descriptions into dynamic videos far beyond static imagery. Models like Mora (Sora Alternative) and Sora have revolutionized this space, turning intricate text prompts into rich, minute-long video narratives. This significant shift—from simple imagery to complex, moving landscapes—highlights the field’s growth and potential. Despite being in its early stages, text-to-video generation is mastering the art of blending visuals and timing to create seamless stories from text, opening new avenues for storytelling and creativity.
Examples of videos created by Mora using prompt
Prompt 1: A vibrant coral reef teeming with life under the crystal-clear blue ocean, with colorful fish swimming among the coral, rays of sunlight filtering through the water, and a gentle current moving the sea plants.
Prompt 2: A majestic mountain range covered in snow, with the peaks touching the clouds and a crystal-clear lake at its base, reflecting the mountains and the sky, creating a breathtaking natural mirror.
Agent-based Video Generation
Definition and Specialization of Agents
In Mora’s universe, agents are akin to members of a film crew, each tasked with a critical role, from scriptwriting to post-production. These agents are meticulously designed to excel in their respective domains, such as interpreting the text, generating imagery, or stitching scenes together. Their specialization ensures that every step of the video generation process is handled with precision and expertise.
Also read: Sora AI: New-Gen Text-to-Video Tool by OpenAI
Mora: A Multi-Agent Framework for Video Generation
Mora stands as a pioneering framework in the realm of video generation, leveraging the collective strengths of multiple AI agents. Each agent within Mora specializes in a distinct aspect of the video creation process, working in harmony to transform text prompts into captivating video narratives. This multi-agent system not only amplifies the efficiency of generating videos but also enhances the creative possibilities, pushing the boundaries of automated video production.
Mora Approaches
Mora adopts a flexible approach to video generation, allowing agents to work either sequentially for straightforward tasks or in parallel when complex multitasking is required. This methodical strategy enables Mora to tackle a wide array of video generation challenges, from simple scene transitions to intricate storytelling, with remarkable adaptability and efficiency.
Implementation Detail of Agents
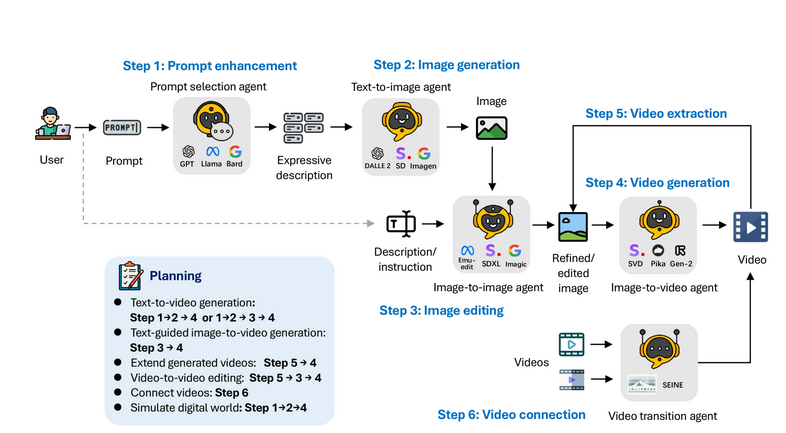
Prompt Selection and Generation
The journey begins with the Prompt Selection and Generation Agent, which meticulously crafts and refines text prompts. This critical first step ensures the prompts are rich in detail and clarity, setting a solid foundation for the visual storytelling that follows. By optimizing the prompts, this agent plays a pivotal role in guiding the subsequent creative process toward coherent and engaging video narratives.
Text-to-Image Generation
Following the prompt refinement, the Text-to-Image Generation Agent takes the baton, translating the enhanced text prompts into initial visual frames. This transformation from text to image is where the first sparks of visual storytelling ignite, setting the stage for the unfolding video narrative.
Image-to-Image Generation
Building on the initial imagery, the Image-to-Image Generation Agent steps in to edit and refine the visuals. Whether adjusting to new prompts or enhancing details, this agent acts as the meticulous editor, ensuring that each frame contributes cohesively to the evolving story.
Image-to-Video Generation
The baton then passes to the Image-to-Video Generation Agent, which breathes life into static images, crafting them into dynamic video sequences. This agent masterfully creates movement and flow, transitioning seamlessly from one frame to the next, thus encapsulating the essence of motion and time.
Connect Videos
Finally, the Connect Videos Agent specializes in weaving separate video segments into a unified narrative. Like a skilled director focusing on continuity, this agent ensures that transitions between clips are smooth and narratively cohesive, maintaining the viewer’s immersion throughout the video experience.
Experiments
The exploration into Mora’s capabilities involves a series of meticulously designed experiments, aiming to benchmark its performance across various video generation tasks against established standards and models, notably comparing against the pioneering Sora.
Also read: 12 Sora AI Features for Creating Photorealistic Videos
Setup Of Mora
Here is the setup of Mora:
Baseline
To anchor the evaluation, the experiments establish a baseline by selecting existing open-source models that exhibit competitive performance in text-to-video generation. This comparison aims to highlight Mora’s position in the landscape of video generation technologies.
Basic Metrics
A comprehensive set of metrics is employed to assess video quality and condition consistency. These include evaluating object and background consistency, motion smoothness, aesthetic quality, dynamic degree, and imaging quality, offering a holistic view of the video output’s fidelity to the original prompts.
Self-defined Metrics
Mora’s evaluation extends beyond standard benchmarks by introducing self-defined metrics tailored to its unique multi-agent framework. These metrics are designed to delve into the nuances of how well the agents’ collaborative efforts translate textual prompts into coherent and visually appealing videos.
Implementation Details
The experimental setup outlines the hardware and software configurations, ensuring a rigorous and reproducible evaluation process. It leverages state-of-the-art GPUs and optimizes the use of PyTorch and CUDA environments, setting the stage for fair and consistent performance assessment across all tasks.
Results After Setup
Lets compare the the output of Mora:
Text-to-Video Generation
Mora’s ability to generate videos from textual descriptions showcases remarkable advancements, with performance metrics closely trailing behind Sora, indicating its potential as a robust tool for creating narrative-driven video content.
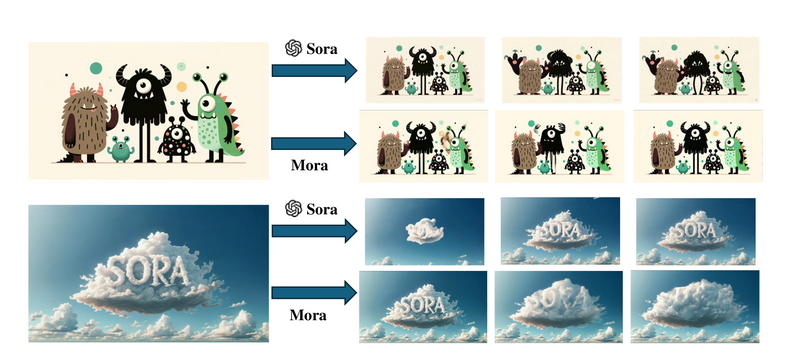
Text-conditional Image-to-Video Generation
This set of experiments evaluates Mora’s proficiency in generating videos based on both textual prompts and initial images. Mora demonstrates an adeptness in this task, reflecting its capability to maintain narrative coherence and visual continuity from the provided images.
Example

Input prompt : Monster Illustration in the flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
Mora Genarated Video

Sora Generated Video

Extend Generated Videos

Mora’s performance in extending the narrative of existing videos further underscores its versatility. The framework exhibits a strong capacity to generate additional sequences that seamlessly continue the storyline and aesthetics of the input videos.
Original Video
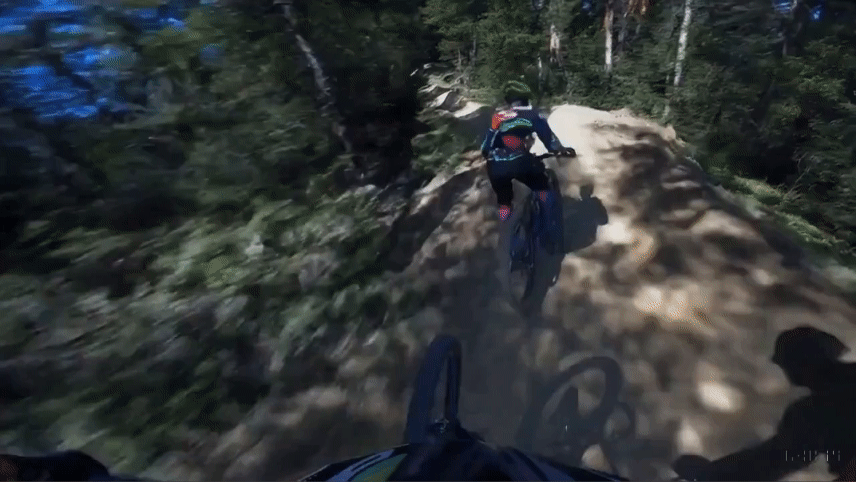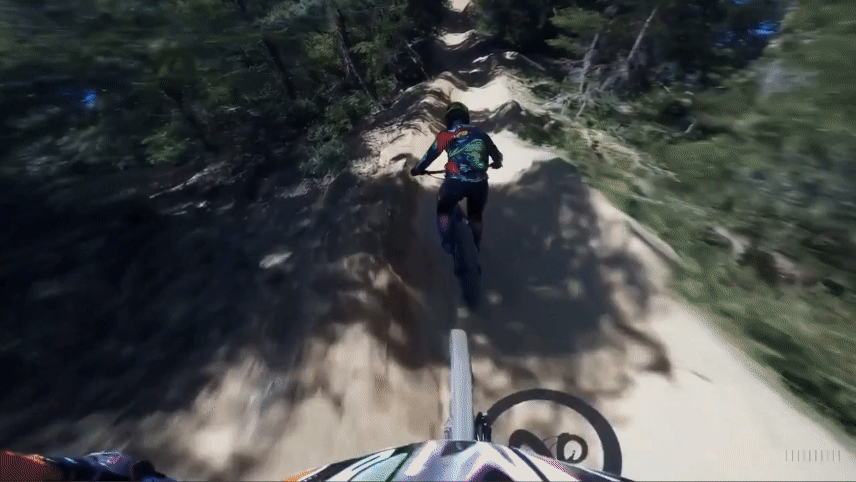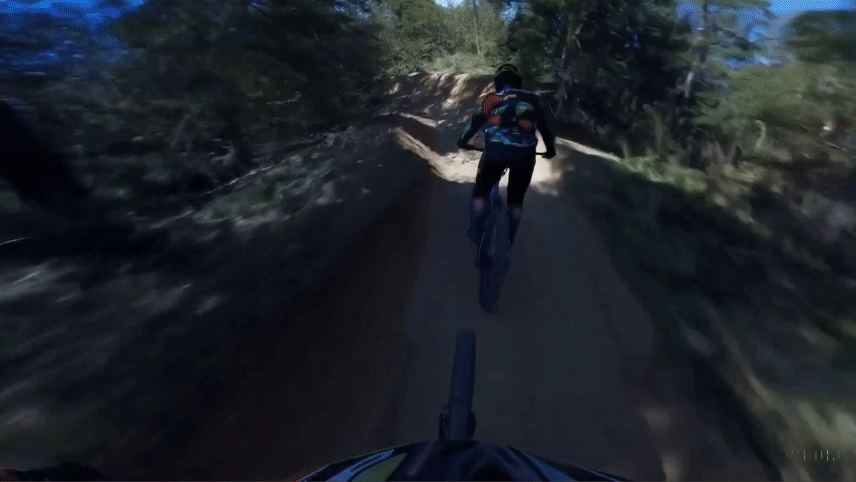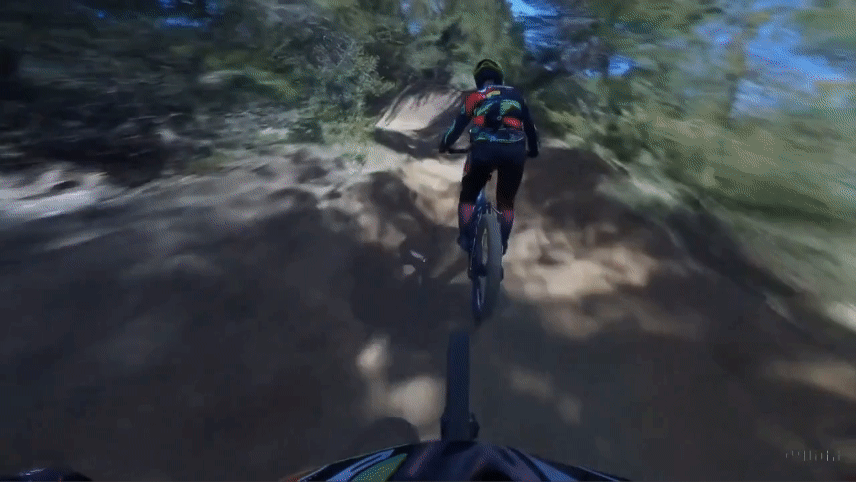
Mora Extended Video

Sora Extended Video

Video-to-Video Editing
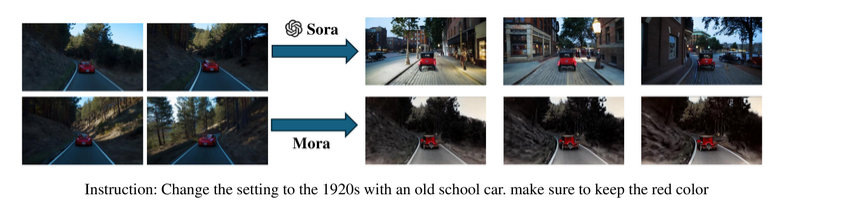
Here is an Original Video

Edited video using prompt
Prompt: Change the setting to the 1920s with an old school car. make sure to keep the red color
Mora edited video

Sora Edited Video

In tasks requiring the editing of videos based on new textual instructions, Mora illustrates significant promise. The experiments highlight its ability to implement detailed edits, altering the visual narrative while maintaining the original video’s core essence.
Connect Videos
Mora’s approach to connecting disparate video segments into a singular, coherent narrative displays its innovative edge. The framework skillfully bridges various scenes, ensuring a smooth narrative flow that enhances the storytelling experience.
Simulate Digital Worlds
Perhaps the most imaginative of Mora’s capabilities is its ability to simulate digital worlds. Through this task, Mora ventures into creating video content that transcends conventional storytelling, generating immersive digital environments based on textual prompts.
Overall, the experimental results portray Mora as a formidable contender in the realm of video generation, showcasing its flexibility, creativity, and technological prowess across a spectrum of tasks. While acknowledging the gap with Sora, these findings herald Mora’s potential to inspire further innovations in the field, paving the way for more accessible and versatile video generation tools.
Also read: Sora:Top 10 Latest Videos By Sora AI
Strengths of Mora
Mora boasts innovative multi-agent framework enabling nuanced video generation, fostering collaborative open-source development, and democratizing access to advanced AI technology. Here are the strenghts of Mora:
Innovative Framework and Flexibility
Mora stands out for its unique approach to video generation. Unlike conventional models that rely on a singular, monolithic structure, Mora’s multi-agent framework offers unparalleled flexibility. This design allows for specialized agents to tackle distinct aspects of the video creation process, enabling a more nuanced and detailed generation of video content. It’s akin to having a team of experts each focusing on their strength, resulting in a harmoniously produced video.
Open-Source Contribution
In a realm where closed-source models like Sora dominate, Mora shines brightly as an open-source beacon. This openness not only fosters a collaborative environment for innovation but also democratizes access to advanced video generation technologies. Mora invites developers, researchers, and creators to dive in, tweak, and improve upon its foundation, propelling the field forward in a collective leap rather than solitary bounds.
Also read: 15+ Best AI Video Generators 2024
Limitations of Mora
Mora faces challenges such as limited access to diverse video datasets, maintaining video quality over longer durations, accurately interpreting complex prompts, and aligning its output with human visual preferences.
Video Dataset Challenges
One significant hurdle Mora faces is the scarcity of high-quality, diverse video datasets. Video generation, especially when aiming for realism and complexity, demands a rich tapestry of data. However, copyright restrictions and the sheer complexity of curating such datasets pose challenges, limiting the training material available for refining Mora’s capabilities.
Quality and Length Gaps
While Mora has shown promise, it grapples with maintaining the fidelity of generated videos, especially as the length increases. This quality and length gap highlight the framework’s current limitations in producing longer videos that remain coherent and visually appealing throughout, a challenge that directly impacts its utility for more extensive storytelling applications.
Instruction Following Capability
Mora’s ambition to follow detailed instructions and generate videos accordingly hits a snag when it comes to interpreting complex, nuanced prompts. The current framework sometimes struggles with accurately translating intricate or abstract textual cues into video content, indicating an area ripe for further development and refinement.
Human Visual Preference Alignment
Lastly, aligning Mora’s output with human visual preferences remains an elusive goal. The subjective nature of aesthetics and storytelling nuances means that what Mora generates might not always resonate with or appeal to all viewers. Bridging this gap requires a deeper understanding of human perception and creativity, a challenge that speaks to the core of artificial intelligence research.
Future Directions for Mora and Video Generation Tech
The future for Mora brims with potential, highlighting the need for agents that can grasp and execute complex prompts with unmatched precision and creativity. Enhancing the quality and continuity of longer videos is crucial, requiring improvements in models and data. Integrating Mora more deeply with human creativity and storytelling, aiming for videos that resonate with a broad spectrum of human preferences, is another vital step forward. Additionally, introducing capabilities for interactive and real-time video creation could transform numerous sectors. With challenges ahead, Mora’s journey is poised for breakthroughs in creativity and innovation, promising a future where video generation technology transcends current limitations, fueled by collaborative effort and the quest for discovery.
Here is the GitHub Link for the Open Source Model of Mora: Mora Github
Conclusion
Mora’s primary contribution lies in its novel multi-agent framework, a paradigm shift from traditional video generation models. This framework not only enhances the flexibility and specificity with which video content can be generated but also opens the door to a collaborative, open-source development environment. By democratizing access to advanced video generation tools, Mora empowers a broader community of creators, researchers, and developers to contribute to and benefit from cutting-edge AI technology. Moreover, Mora’s experimental results underscore its capability to create compelling video content from textual descriptions, bridging the gap between text and visual narrative in new and exciting ways.

