
In the dynamic realm of language model development, a recent groundbreaking paper titled “Direct Preference Optimization (DPO)” by Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Chris Manning, and Chelsea Finn, has captured the attention of AI luminaries like Andrew Ng. This article delves into the revolutionary aspects of DPO and its potential to redefine the future of language models.
Andrew Ng, recently expressed his profound admiration for DPO. In his view, this research represents a significant simplification over traditional methods like Reinforcement Learning from Human Feedback (RLHF) for aligning language models to human preferences. Ng lauds the paper for demonstrating that significant advancements in AI can stem from deep algorithmic and mathematical insights, even without immense computational resources.

Key Concepts
Understanding the Complexity of Traditional Language Models
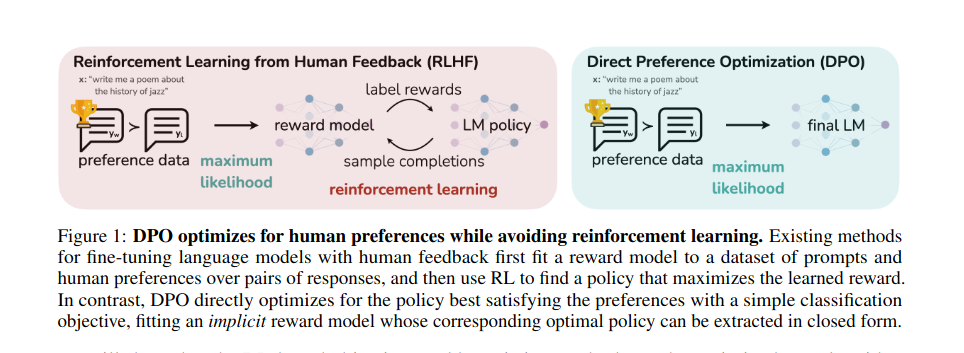
Traditionally, the alignment of language models with human preferences has been achieved through a complex process known as Reinforcement Learning from Human Feedback (RLHF). This method involves a multi-stage process:
- Supervised Fine-Tuning (SFT): RLHF begins with a pre-trained language model, which is then fine-tuned on high-quality datasets for specific applications.
- Preference Sampling and Reward Learning: This phase entails collecting human preferences between pairs of language model outputs and using these preferences to learn a reward function, typically employing the Bradley-Terry model.
- Reinforcement Learning Optimization: The final phase uses the learned reward function to further fine-tune the language model, focusing on maximizing the reward for the outputs while maintaining proximity to its original training.
Direct Preference Optimization (DPO)
The paper introduces DPO, a new parameterization of the reward model in RLHF, which enables the extraction of the corresponding optimal policy in a closed form. This approach simplifies the RLHF problem to a simple classification loss, making the algorithm stable, performant, and computationally lightweight. DPO innovates by combining the reward function and language model into a single transformer network. This simplification means only the language model needs training, aligning it with human preferences more directly and efficiently. The elegance of DPO lies in its ability to deduce the reward function the language model is best at maximizing, thereby streamlining the entire process.
I asked ChatGPT to explain the above to a 5 year old and here is the result (hope you get a better understanding, let me know in comments):
“Imagine you have a big box of crayons to draw a picture, but you're not sure which colors to choose to make the most beautiful picture. Before, you had to try every single crayon one by one, which took a lot of time. But now, with something called Direct Preference Optimization (DPO), it's like having a magical crayon that already knows your favorite colors and how to make the prettiest picture. So, instead of trying all the crayons, you use this one special crayon, and it helps you draw the perfect picture much faster and easier. That's how DPO works; it helps computers learn what people like quickly and easily, just like the magical crayon helps you make a beautiful drawing.”
Comparison with RLHF
DPO is shown to fine-tune LMs to align with human preferences as well or better than existing methods, including PPO-based RLHF. It excels in controlling the sentiment of generations and matches or improves response quality in summarization and single-turn dialogue tasks. DPO is simpler to implement and train compared to traditional RLHF methods.
Technical Details
- DPO’s Mechanism: DPO directly optimizes for the policy best satisfying the preferences with a simple binary cross-entropy objective, fitting an implicit reward model whose corresponding optimal policy can be extracted in closed form.
- Theoretical Framework: DPO relies on a theoretical preference model, like the Bradley-Terry model, that measures how well a given reward function aligns with empirical preference data. Unlike existing methods that train a policy to optimize a learned reward model, DPO defines the preference loss as a function of the policy directly.
- Advantages: DPO simplifies the preference learning pipeline significantly. It eliminates the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning.
Experimental Evaluation
- Performance on Tasks: Experiments demonstrate DPO’s effectiveness in tasks such as sentiment modulation, summarization, and dialogue. It shows comparable or superior performance to PPO-based RLHF while being substantially simpler.
- Theoretical Analysis: The paper also provides a theoretical analysis of DPO, relating it to issues with actor-critic algorithms used for RLHF and demonstrating its advantages.
DPO vs RLHF
1. Methodology
- DPO: Direct Preference Optimization focuses on directly optimizing language models to adhere to human preferences. It operates without explicit reward modeling or reinforcement learning, simplifying the training process. DPO optimizes the same objectives as RLHF but with a straightforward binary cross-entropy loss. It increases the relative log probability of preferred responses and uses a dynamic importance weight to prevent model degeneration.
- RLHF: Reinforcement Learning from Human Feedback typically involves a complex procedure that includes fitting a reward model based on human preferences and fine-tuning the language model using reinforcement learning to maximize this estimated reward. This process is more computationally intensive and can be unstable.
2. Implementation Complexity
- DPO: Easier to implement due to its simplicity and direct approach. It does not require significant hyperparameter tuning or sampling from the language model during fine-tuning.
- RLHF: Involves a more complex and often unstable training process with reinforcement learning, requiring careful hyperparameter tuning and potentially sampling from the language model.
3. Efficiency and Performance
- DPO: Demonstrates at least equal or superior performance to RLHF methods, including PPO-based RLHF, in tasks like sentiment modulation, summarization, and dialogue. It is also computationally lightweight and provides a stable training environment.
- RLHF: While effective in aligning language models with human preferences, it can be less efficient and stable compared to DPO, especially in large-scale implementations.
4. Theoretical Foundation
- DPO: Leverages an analytical mapping from reward functions to optimal policies, enabling a transformation of a loss function over reward functions into a loss function over policies. This avoids fitting an explicit standalone reward model while still optimizing under existing models of human preferences.
- RLHF: Typically relies on a more traditional reinforcement learning approach, where a reward model is trained based on human preferences, and then a policy is trained to optimize this learned reward model.
5. Empirical Results:
- DPO: In empirical evaluations, DPO has shown to produce more efficient frontiers in terms of reward/KL tradeoff compared to PPO, achieving higher rewards while maintaining low KL. It also demonstrates better performance in fine-tuning tasks like summarization and dialogue.
- RLHF: PPO and other RLHF methods, while effective, may not achieve as efficient a reward/KL tradeoff as DPO. They may require access to ground truth rewards for optimal performance, which is not always feasible.
Impact and Future Prospects
Andrew anticipates that DPO will significantly influence language models in the coming years. This method has already been integrated into high-performing models like Mistral’s Mixtral, indicating its immediate applicability. Ng’s optimism is tempered with caution, acknowledging that the long-term impact remains to be seen.
This development underscores the ongoing innovation within the field of AI. Ng emphasizes that groundbreaking work isn’t exclusive to organizations with vast resources; deep thinking and a modest computational setup can yield significant breakthroughs. He also notes a media bias towards big tech companies, suggesting that research like DPO deserves broader recognition.
Final Thought
Direct Preference Optimization presents a powerful and scalable framework for training language models aligned with human preferences, reducing the complexity traditionally associated with RLHF algorithms. Its emergence is a clear sign that the field of AI, particularly in language model development, is ripe for innovation and growth. With DPO, the future of language models seems poised for significant advancements, driven by insightful algorithmic and mathematical research.
Additional Helpful Links:

