
Introduction
Creating visually engaging content can be a time-consuming task for bloggers and creators. After crafting a compelling article, finding the right images is often a separate challenge. But what if Blog Creation with AI could do it all for you? Imagine a seamless process where, alongside your writing, AI generates original, high-quality images tailored to your article and even provides captions for them.
This article delves into building a fully automated system of blog creation with AI for image generation and captioning, simplifying the blog creation workflow. The approach here involves using traditional Natural Language Processing (NLP) to summarize the article into a short sentence, capturing the essence of your blog. We then use this sentence as a prompt for automated image generation via Stable Diffusion, followed by using an image-to-text model to create captions for those images.
Learning Objectives
- Understand how to integrate AI-based image generation using text ‘prompts’.
- Automating Blog Creation with AI for captioning.
- Learn the fundamentals of traditional NLP for text summarization.
- Explore how to utilize the Segmind API for automated image generation, enhancing your blog with visually appealing content.
- Gain practical experience with Salesforce BLIP for image captioning.
- Build a REST API to automate summarization, image generation, and captioning.
This article was published as a part of the Data Science Blogathon.
What is Image-to-Text in GenAI?
Image-to-text in Generative AI (GenAI) refers to the process of generating descriptive text (captions) from images. This is done using machine learning models trained on large datasets, where the model learns to identify objects, people, and scenes in an image and generates a coherent text description. Such models are useful in applications, from automating content creation to improving accessibility for the visually impaired.
What is Image Captioning?
Image captioning is a subfield of computer vision where a system generates textual descriptions for images. It involves understanding the contents of an image and describing it in a way that is meaningful and correct. The model usually combines techniques from both vision (for image understanding) and language modeling (for generating text).
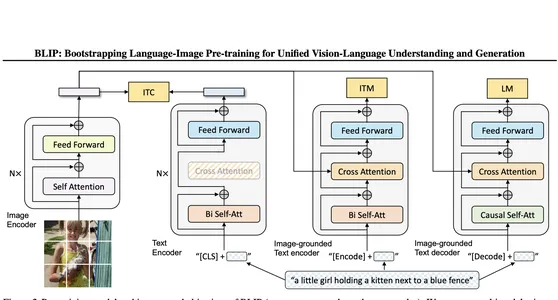
Introduction to the Salesforce BLIP Model
BLIP (Bootstrapping Language-Image Pretraining) is a model from Salesforce that leverages vision and language processing for tasks like image captioning, visual question answering, and multimodal understanding. The model is trained on massive datasets and is known for its ability to generate accurate and contextually rich captions for images. We are considering this model for our captioning. We will get it from HuggingFace.
What is Segmind API?
Segmind is a platform that provides services to facilitate Generative AI workflows, primarily through API calls. Developers and enterprises can use it to generate images from text ‘prompts’, making use of diverse models in the cloud without needing to manage the computational resources themselves. Segmind’s API allows you to create images in styles—ranging from realistic to artistic—while customizing them to fit your brand’s visual identity. For this project, we’ll use the free Segmind API to generate images, ensuring that we don’t have to worry about running image models locally. You can sign up and create an API key here.
We will be using the new image model from Black Forest Labs called FLUX which is available on Segmind. You can get them from hugging face diffusers or read the docs here.
Overview of NLP for Text Summarization
Natural Language Processing (NLP) is a subfield of artificial intelligence focused on the interaction between computers and human (natural) language. It enables computers to understand, interpret, and generate human language. Applications of NLP include text analysis, sentiment analysis, language translation, text generation, and text summarization. In this project, we’ll be using NLP specifically for text summarization.
Why Traditional NLP and Not LLM for Text Summarization?
The text summarization in this project is not meant for end users but will be used as a ‘prompt’ for the Stable Diffusion model. Traditional NLP techniques, whether extractive or abstractive summarization, are sufficient for creating image-generation ‘prompts’. In fact, even simple keyword extraction would work. While using Large Language Models (LLMs) could make the summary smoother by introducing contextual understanding, it’s not necessary in this case, as the generated summary only serves as a ‘prompt’. Additionally, using traditional NLP saves computational costs compared to LLMs. Knowing when to use LLMs versus traditional NLP is key to optimizing both performance and cost.
Overview of the System:
- Text Analysis: Use NLP techniques to summarize the article.
- Image Generation: Use Segmind API to generate images based on the summary.
- Image Captioning: Use Salesforce BLIP to caption the generated images.
- REST API: Build an endpoint that accepts article text or URL and returns the image with a caption.
Step-by-Step Code Implementation
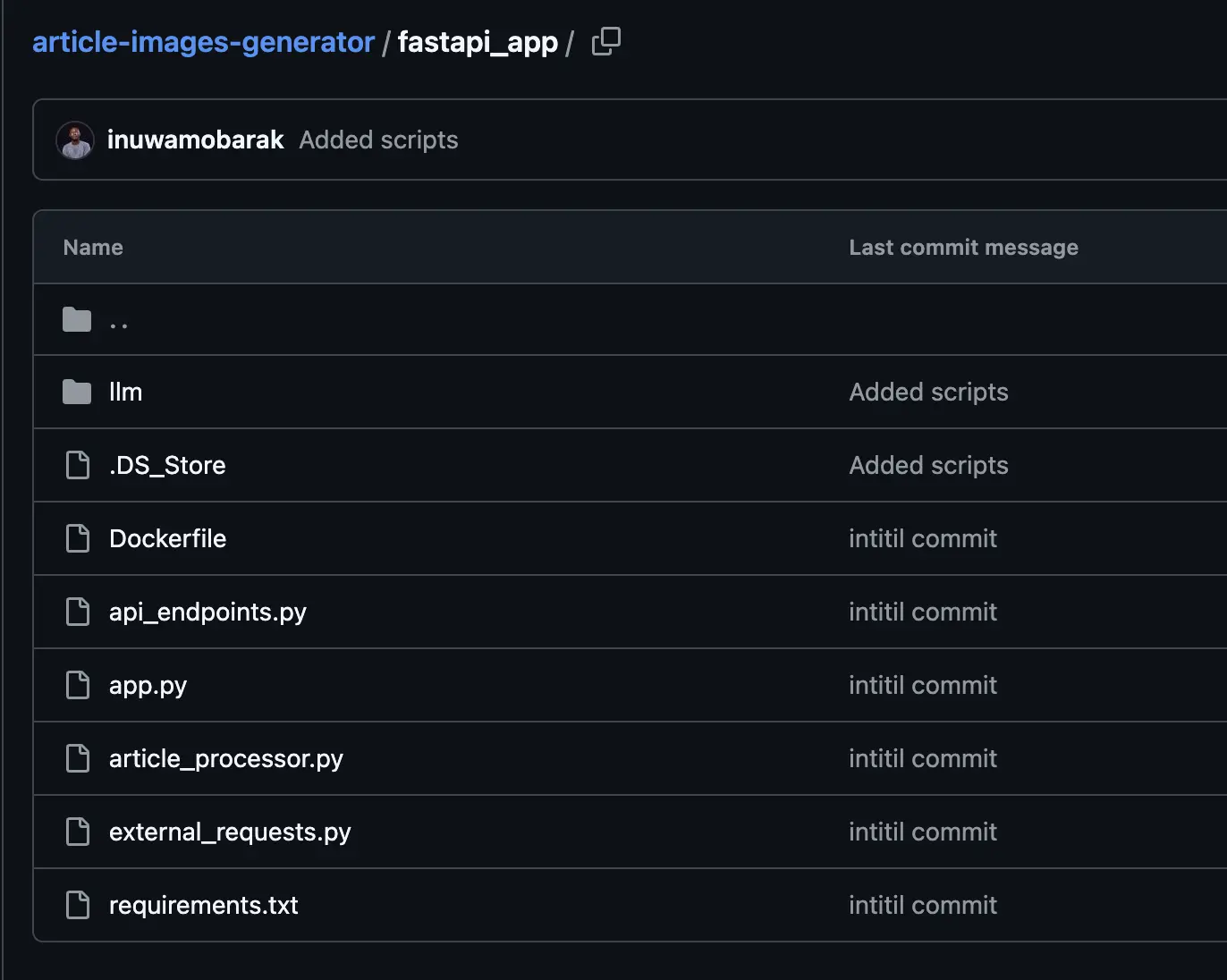
Create a folder/directory called fastapi_app. Add all the files in the screenshot below. The other folder will be created later which will hold an optional UI.
Here is the entire code in this repo.
Step 1: Install Dependencies
Before going into the main steps, let us install requirements. We have up to 15 packages we need to install so we will just use a requirements.txt file to do this. Create it and add the following packages:
beautifulsoup4
lxml
nltk
fastapi
fastcore
uvicorn
pytest
llama-cpp-python==0.2.82
pydantic==2.8.2
torch
diffusers
accelerate
litserve
transformers
streamlitNow go to that directory in terminal and run this command:
pip install -r requirements.txtWe will start with building the text summarizer with NLP. open the article_processor.py and import the following libraries:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from bs4 import BeautifulSoup
import urllib.request
import heapq
import reNext, we need to download some resources for our NLP toolkit:
# Download required NLTK resources
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')We need a class we can call with our article that can do the summarization and return the summary. I have added a docstring to grasp what the class will do entirely. Here is the class:
class TextSummarizer:
"""
A class used to summarize text from a given input.
Attributes:
----------
input_data : str
The text to be summarized. Can be a URL or a string of text.
num_sentences : int
The number of sentences to include in the summary.
is_url : bool
Whether the input_data is a URL or not.
Methods:
-------
__init__(input_data, num_sentences)
Initializes the TextSummarizer object.
check_if_url(input_data)
Checks if the input_data is a URL.
fetch_article()
Fetches the article from the given URL.
parse_article(article)
Parses the article and extracts the text.
calculate_word_frequencies(article_text)
Calculates the frequency of each word in the article.
calculate_sentence_scores(article_text, word_frequencies)
Calculates the score of each sentence based on the word frequencies.
summarize()
Summarizes the text and returns the summary.
"""
def __init__(self, input_data, num_sentences):
self.input_data = input_data
self.num_sentences = num_sentences
self.is_url = self.check_if_url(input_data)
def check_if_url(self, input_data):
# Simple regex to check if the input is a URL
url_pattern = re.compile(r'^(http|https)://')
return re.match(url_pattern, input_data) is not None
def fetch_article(self):
wikipedia_article = urllib.request.urlopen(self.input_data)
article = wikipedia_article.read()
return article
def parse_article(self, article):
parsed_article = BeautifulSoup(article, 'lxml')
paragraphs = parsed_article.find_all('p')
article_text = ""
for p in paragraphs:
article_text += p.text
return article_text
def calculate_word_frequencies(self, article_text):
stopwords_list = stopwords.words('english')
word_frequencies = {}
for word in word_tokenize(article_text):
if word not in stopwords_list:
if word not in word_frequencies.keys():
word_frequencies[word] = 1
else:
word_frequencies[word] += 1
maximum_frequency = max(word_frequencies.values())
for word in word_frequencies.keys():
word_frequencies[word] = (word_frequencies[word] / maximum_frequency)
return word_frequencies
def calculate_sentence_scores(self, article_text, word_frequencies):
sentence_list = sent_tokenize(article_text)
sentence_scores = {}
for sent in sentence_list:
for word in word_tokenize(sent.lower()):
if word in word_frequencies.keys():
if len(sent.split(' ')) < 32:
if sent not in sentence_scores.keys():
sentence_scores[sent] = word_frequencies[word]
else:
sentence_scores[sent] += word_frequencies[word]
return sentence_scores
def summarize(self):
"""
Summarizes the text and returns the summary.
Returns:
-------
str
The summary text.
"""
if self.is_url:
# If the input is a URL, fetch and parse the article
article = self.fetch_article()
article_text = self.parse_article(article)
else:
# If the input is not a URL, use the input text directly
article_text = self.input_data
# Calculate the word frequencies and sentence scores
word_frequencies = self.calculate_word_frequencies(article_text)
sentence_scores = self.calculate_sentence_scores(article_text, word_frequencies)
# Get the top-scoring sentences for the summary
summary_sentences = heapq.nlargest(self.num_sentences, sentence_scores, key=sentence_scores.get)
# Join the summary sentences into a single string
summary = ''.join(summary_sentences)
return summaryStep 2: External API Call for Segmind API
Now open the external request and add the request to Segmind. I have added a docstring to grasp the class better.
import requests
class SegmindAPI:
"""
A class used to interact with the Segmind API.
Attributes:
----------
api_key : str
The API key for the Segmind API.
url : str
The base URL for the Segmind API.
Methods:
-------
__init__(api_key)
Initializes the SegmindAPI object.
generate_image(prompt, steps, seed, aspect_ratio, base64=False)
Generates an image using the Segmind API.
"""
def __init__(self, api_key):
self.api_key = api_key
self.url = "https://api.segmind.com/v1/fast-flux-schnell"
def generate_image(self, prompt, steps, seed, aspect_ratio, base64=False):
# Create the data payload for the API request
data = {
"prompt": prompt,
"steps": steps,
"seed": seed,
"aspect_ratio": aspect_ratio,
"base64": base64
}
headers = {
"x-api-key": self.api_key
}
response = requests.post(self.url, json=data, headers=headers)
if response.status_code == 200:
with open("image.png", "wb") as f:
f.write(response.content)
print("Image saved to image.png")
return response
else:
print(f"Error: {response.text}")
return NoneWe will call this class generate_image to get our article image from Segmind API.
Step 3: Image Caption with Blip
Since we are loading blip from hugging face API, for simplicity, we will initialize it in our api_endpoints.py. But if you wish you can make it a separate file or better still include it in the script for segmind API.
from fastapi import FastAPI, HTTPException
from fastapi.responses import FileResponse
from PIL import Image
import base64
from article_processor import TextSummarizer
from external_requests import SegmindAPI
from pydantic import BaseModel
from transformers import BlipProcessor, BlipForConditionalGeneration
from llm.inference import LlmInference
inference = LlmInference()
app = FastAPI()
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
Step 4: Prepare Endpoint for Interacting with our classes
Now we will update the api_endpoints.py file by adding 3 endpoints. One endpoint will be for simple generating images, the second and third will generate both image and caption but in carious format depending on how tyou want to get the image.
class ImageRequest(BaseModel):
"""A Pydantic model for image requests"""
# text: str = None
url: str = None
num_sentences: int
steps: int
seed: int
aspect_ratio: str
class ArticleRequest(BaseModel):
"""A Pydantic model for article requests"""
description: str = None
num_sentences: int
steps: int
seed: int
aspect_ratio: str
@app.post("/generate_image")
async def generate_image(image_request: ImageRequest):
"""
Generates an image based on the summary of an article.
Parameters:
----------
image_request : ImageRequest
The request containing the article URL and image generation parameters.
Returns:
-------
FileResponse
The generated image as a PNG file.
"""
try:
api_key = "your_api_key_here" # Use a .env to make this a secret
api = SegmindAPI(api_key)
summarizer = TextSummarizer(image_request.url, image_request.num_sentences)
summary = summarizer.summarize()
response = api.generate_image(summary, image_request.steps, image_request.seed, image_request.aspect_ratio,
False)
if response is not None:
return FileResponse("image.png", media_type="image/png")
else:
raise HTTPException(status_code=500, detail="Error generating image")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/generate_image_caption")
async def generate_image_caption(image_request: ImageRequest):
"""
Generates an image and its caption based on the summary of an article.
Parameters:
----------
image_request : ImageRequest
The request containing the article URL and image generation parameters.
Returns:
-------
dict
A dictionary containing the encoded image and its caption.
"""
try:
api_key = "your_api_key_here" # Use a .env to make this a secret
api = SegmindAPI(api_key)
summarizer = TextSummarizer(image_request.url, image_request.num_sentences)
summary = summarizer.summarize()
response = api.generate_image(summary, image_request.steps, image_request.seed, image_request.aspect_ratio,
False)
if response is not None:
image = Image.open("image.png")
inputs = processor(image, text="a cover photo of", return_tensors="pt")
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
with open("image.png", "rb") as image_file:
encoded_image = base64.b64encode(image_file.read()).decode('utf-8')
return {"image": encoded_image, "caption": caption}
else:
raise HTTPException(status_code=500, detail="Error generating image")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/generate_article_and_image_caption")
async def generate_article_and_image_caption(article_request: ArticleRequest):
"""
Generates an article and its image caption.
Parameters:
----------
article_request : ArticleRequest
The request containing the article description and image generation parameters.
Returns:
-------
dict
A dictionary containing the encoded image and its caption.
"""
num_sentences=article_request.num_sentences
try:
api_key = "your_api_key_here" # Use a .env to make this a secret
api = SegmindAPI(api_key)
# Generate article with llm
article = inference.generate_article(article_request.description)
# Summarize article
summarizer = TextSummarizer(input_data=article, num_sentences=num_sentences)
summary = summarizer.summarize()
# Generate image with Segmind
response = api.generate_image(summary, article_request.steps, article_request.seed,
article_request.aspect_ratio,
False)
if response is not None:
image = Image.open("image.png")
inputs = processor(image, text="a cover photo of", return_tensors="pt")
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
with open("image.png", "rb") as image_file:
encoded_image = base64.b64encode(image_file.read()).decode('utf-8')
return {"image": encoded_image, "caption": caption}
else:
raise HTTPException(status_code=500, detail="Error generating image")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))No you can start the FastAPI server a using this command:
uvicorn api_endpoints:app --host 0.0.0.0 --port 8000you can find the endpoint here in your local server:
http://127.0.0.1:8000/docsTo test your code send this payload in terminal:
{"url": "https://en.wikipedia.org/wiki/History_of_Poland_(1945%E2%80%931989)", "num_sentences": 5, "steps": 4, "seed": 1184522, "aspect_ratio": "1:1"}The endpoint will return a JSON with two fields. One is “image” and the other is “caption”. To follow best practice we return the image encoded as base64. To view the actual image, you need to convert the base64 normal image. Copy the image content and click here. Paste the base64 string there and it will show you the generated image.
This is the generated image and image caption for the article on the History of Poland:

Generated caption: “a cover photo of a man in a military uniform”
Example 2: Wikipedia Article related to Nigeria
{"url": "https://en.wikipedia.org/wiki/Nigeria#Health", "num_sentences": 5, "steps": 4, "seed": 1184522, "aspect_ratio": "1:1"}
caption: “a cover photo of the republic of nigeria”
Adding a UI with Streamlit
We will add a simple UI for our app using Streamlit. Create another directory called streamlit_app:
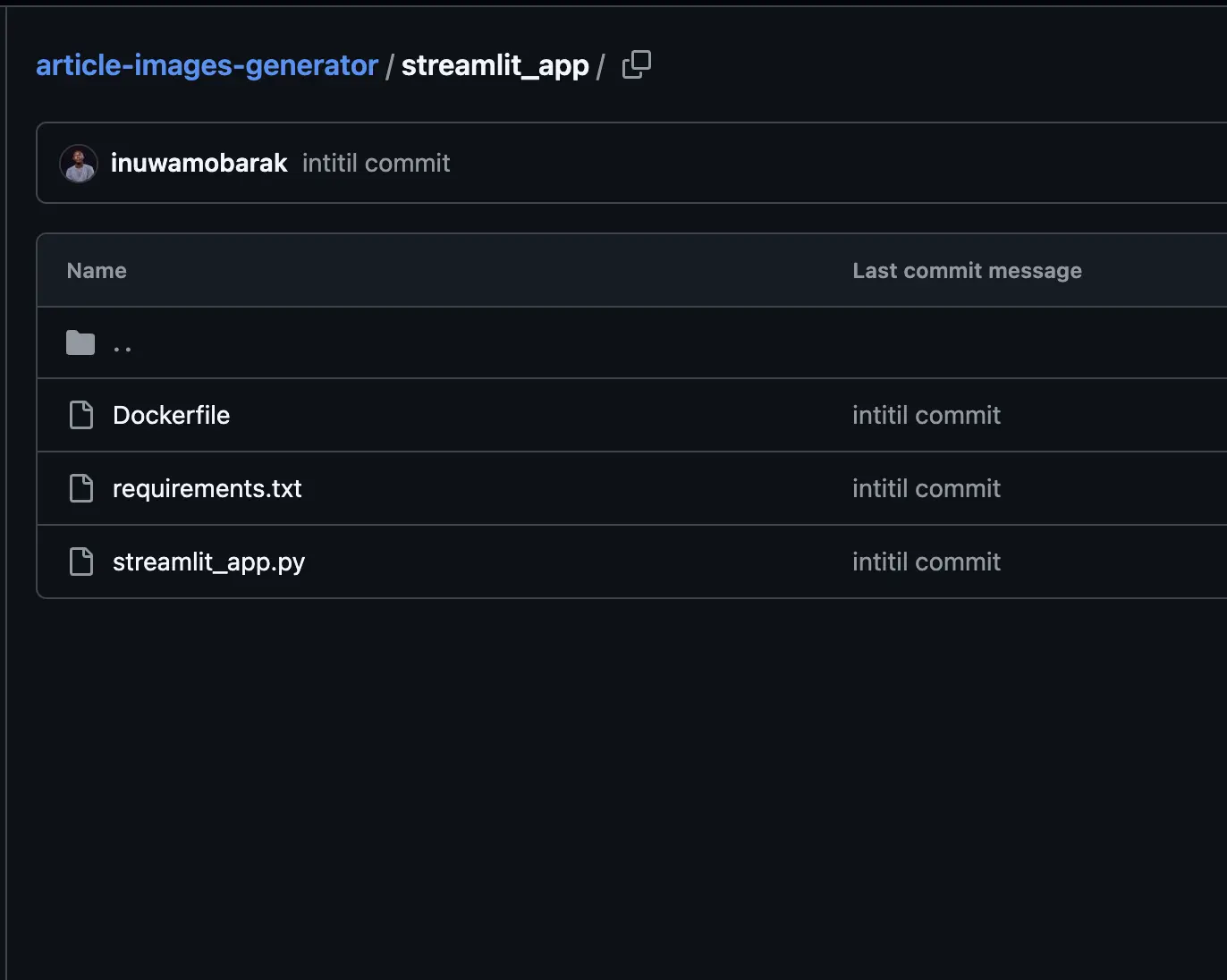
Lets create the streamlit_app.py:
import streamlit as st
import requests
from PIL import Image
from io import BytesIO
import base64
st.title("Article Image and Caption Generator")
# Input fields
url = st.text_input("Enter the article URL")
num_sentences = st.number_input("Number of sentences to summarize to", min_value=1, value=3)
steps = st.number_input("Steps for image generation", min_value=1, value=50)
seed = st.number_input("Random seed for generation", min_value=0, value=42)
aspect_ratio = st.selectbox("Select Aspect Ratio", ["16:9", "4:3", "1:1"])
# Button to trigger the generation
if st.button("Generate Image and Caption"):
# Show a spinner while generating
with st.spinner("Generating..."):
# Send a POST request to the FastAPI endpoint
response = requests.post(
"http://fastapi:8000/generate_image_caption", # Use service name defined in docker-compose
json={
"url": url,
"num_sentences": num_sentences,
"steps": steps,
"seed": seed,
"aspect_ratio": aspect_ratio
}
)
# Check if the response was successful
if response.status_code == 200:
# Get the response data
data = response.json()
caption = data["caption"]
image_data = base64.b64decode(data["image"])
# Open the image from the response data
image = Image.open(BytesIO(image_data))
# Display the image with its caption
st.image(image, caption=caption, use_column_width=True)
else:
st.error(f"Error: {response.json()['detail']}")To start the Streamlit app and see the UI in your browser, run `streamlit run streamlit_app.py`
If you see this on terminal then all is well:
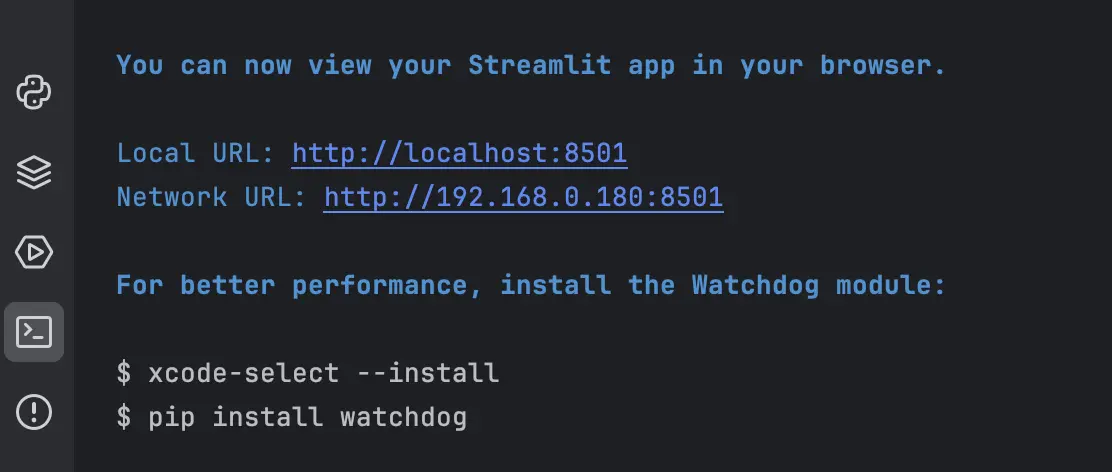

Output:

You can modify the code and the image generation parameters for automated image generation to get different kinds of images, and even utilize models from Segmind or the BLIP model for captioning. Feel free to implement the section for article generation before passing that article for automated image generation. The possibilities are many, so enjoy skilling up and building AI apps!
Conclusion
By combining traditional NLP with the power of generative AI, we’ve created a system that simplifies the blog-writing process. With the help of the Segmind API for automated image generation and Salesforce BLIP for captioning, you can now automate the creation of original visuals that enhance your written content. This not only saves time but ensures that your blogs remain visually appealing and informative. The integration of AI into creative workflows is a game-changer, making content creation more efficient and scalable, particularly through automated image generation.
Key Takeaways
- AI can generate images and captions for blogs, significantly reducing the need for manual search through automated image generation.
- Traditional NLP methods save on computational costs while still generating ‘prompts’ for image creation.
- The Segmind API allows high-quality, cloud-based image generation, facilitating automated image generation for various applications.
- AI-driven captions provide contextual relevance to generated images, improving blog content quality.
References and Links
Frequently Asked Questions
A. Traditional NLP summarization extracts or generates summaries using simple rule-based methods, while LLMs use deep learning models to provide more context-aware and fluent summaries. For image generation, traditional NLP suffices.
A. Segmind API allows cloud-based image generation, saving computational resources and eliminating the need to set up or maintain local models.
A. BLIP (Bootstrapping Language-Image Pretraining) is used to generate captions for the images produced by the AI. It converts images to meaningful text.
A. You can adjust the summary, ‘prompt’, or image generation parameters (like steps, seed, and aspect ratio) to fine-tune the outputs.
A. Blog Creation with AI automates tasks like image generation, captioning, and text summarization, significantly speeding up and simplifying the content production process.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an AI Engineer with a deep passion for research, and solving complex problems. I provide AI solutions leveraging Large Language Models (LLMs), GenAI, Transformer Models, and Stable Diffusion.

