
Introduction
Image matting technology is a computer vision and image processing technique that separates the foreground objects from the background in an image. The goal of image matting is to accurately compute the transparency or alpha values for each pixel in the image, indicating how much of the pixel belongs to the foreground and how much to the background.
Various applications commonly use image matting, including image and video editing, which requires precise object extraction. It allows for creating realistic composites, seamlessly integrating objects from one image into another while preserving intricate details like hair or fur. Advanced image matting techniques often involve using machine learning models and deep learning algorithms to improve the accuracy of the matting process. These models analyze the image’s visual characteristics, including color, texture, and lighting, to effectively estimate the alpha values and separate foreground and background elements.
Image matting involves accurately estimating the foreground object in an image. People employ this technique in various applications, with one notable example being the use of background blur effects during video calls or when capturing portrait selfies on smartphones. ViTMatte is the latest addition to the 🤗 Transformers library, a state-of-the-art model designed for image matting. ViTMatte leverages a vision transformer (ViT) as its backbone, complemented by a lightweight decoder, making it capable of distinguishing intricate details such as individual hairs.
Learning objectives
In this article, we’ll delve into;
- The ViTMatte model and demonstrate it for image matting.
- We’ll provide a step-by-step guide using code
This article was published as a part of the Data Science Blogathon.
Understanding the ViTMatte Model
ViTMatte’s architecture is built upon a vision transformer (ViT), the model’s backbone. The key advantage of this design is that the backbone handles the heavy lifting, benefiting from large-scale self-supervised pre-training. This results in high performance when it comes to image matting. It was introduced in the paper “Boosting Image Matting with Pretrained Plain Vision Transformers” by Jingfeng Yao, Xinggang Wang, Shusheng Yang, and Baoyuan Wang. This model leverages the power of plain Vision Transformers (ViTs) to tackle image matting, which involves accurately estimating the foreground object in images and videos.
The critical contributions of ViTMatte, as in the abstract of the paper, are as follows:
- Hybrid Attention Mechanism: It uses a hybrid attention mechanism with a convolutional “neck.” This approach helps ViTs strike a balance between performance and computation in matting.
- Detail Capture Module: To better information crucial for matting, ViTMatte introduces the detail capture module. This module consists of lightweight convolutions, which complement the information.
ViTMatte inherits several traits from ViTs, including diverse pretraining strategies, streamlined architectural design, and adaptable inference strategies.
State-of-the-Art Performance
The model was evaluated on Composition-1k and Distinctions-646, benchmarks for image matting. In both cases, ViTMatte has achieved state-of-the-art performance and surpassed the capabilities of past matting methods by a margin. This underscores ViTMatte’s potential in the field of image matting.
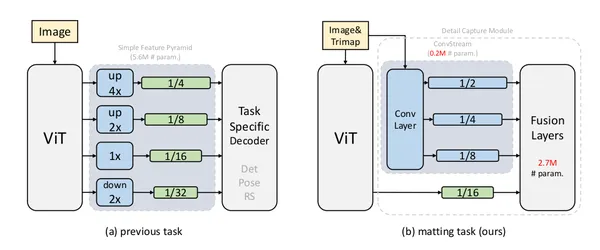
The above diagram is from their paper showing an overview of ViTMatte and other applications of plain vision transformers. The past approach used a simple feature pyramid designed by ViTDet. Figure (b) presents a new adaptation strategy for image matting called ViTMatte. It leverages simple convolution layers to extract information from the image and utilizes the feature map generated by vision transformers (ViT).
Practical Implementation
Let’s dive into the practical implementation of ViTMatte. We will walk through the steps to use ViTMatte to harness its capabilities. We can not continue this article without mentioning the efforts of Niels Rogge for his constant efforts for the HF family. ViTMatte’s contribution to HF is attributed to Niels https://huggingface.co/nielsr. The original code for ViTMatte can be found here. Let us dive into the code!
Setting Environment
To get started with ViTMatte, you first need to set up your environment. Find this tutorial code here: https://github.com/inuwamobarak/ViTMatte . Begin by installing the 🤗 Transformers library, which includes the ViTMatte model. Use the following code for installation:
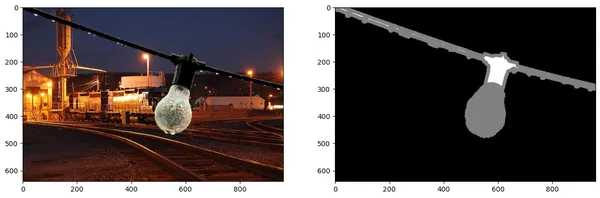
!pip install -q git+https://github.com/huggingface/transformers.gitLoading the Image and Trimap
In image matting, we manually label a hint map known as a trimap, which outlines the foreground in white, the background in black, and the unknown regions in grey. The ViTMatte model expects both the input image and the trimap to perform image matting.
The below code demonstrates loading an image and its corresponding trimap:
# Import necessary libraries
import matplotlib.pyplot as plt
from PIL import Image
import requests
# Load the image and trimap
url = "https://github.com/hustvl/ViTMatte/blob/main/demo/bulb_rgb.png?raw=true"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
url = "https://github.com/hustvl/ViTMatte/blob/main/demo/bulb_trimap.png?raw=true"
trimap = Image.open(requests.get(url, stream=True).raw)
# Display the image and trimap
plt.figure(figsize=(15, 15))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.imshow(trimap)
plt.show()
Loading the ViTMatte Model
Next, let’s load the ViTMatte model and its processor from the 🤗 hub. The processor handles the image preprocessing, while the model itself is the core for image matting.
# Import ViTMatte related libraries
from transformers import VitMatteImageProcessor, VitMatteForImageMatting
# Load the processor and model
processor = VitMatteImageProcessor.from_pretrained("hustvl/vitmatte-small-distinctions-646")
model = VitMatteForImageMatting.from_pretrained("hustvl/vitmatte-small-distinctions-646")Running a Forward Pass
Now that we’ve set the image and trimap and the model, let’s run a forward pass for the predicted alpha values. These alpha values represent the transparency of each pixel in the image. This means that with the model and processor in place, you can now perform a forward pass to get the predicted alpha values, which represent the transparency of each pixel in the image.
# Import necessary libraries
import torch
# Perform a forward pass
with torch.no_grad():
outputs = model(pixel_values)
# Extract the alpha values
alphas = outputs.alphas.flatten(0, 2)Visualizing the Foreground
To visualize the foreground object, we can use the following code, which crops the foreground from the image based on the predicted alpha values:
# Import necessary libraries
import PIL
from torchvision.transforms import functional as F
# Define a function to calculate the foreground
def cal_foreground(image: PIL.Image, alpha: PIL.Image):
image = image.convert("RGB")
alpha = alpha.convert("L")
alpha = F.to_tensor(alpha).unsqueeze(0)
image = F.to_tensor(image).unsqueeze(0)
foreground = image * alpha + (1 - alpha)
foreground = foreground.squeeze(0).permute(1, 2, 0).numpy()
return foreground
# Calculate and display the foreground
fg = cal_foreground(image, prediction)
plt.figure(figsize=(7, 7))
plt.imshow(fg)
plt.show()
Background Replacement
One impressive use of image matting is replacing the background with a new one. The code below shows how to merge the predicted alpha matte with a new background image:
# Load the new background image
url = "https://github.com/hustvl/ViTMatte/blob/main/demo/new_bg.jpg?raw=true"
background = Image.open(requests.get(url, stream=True).raw).convert("RGB")
plt.imshow(background)
# Define a function to merge with the new background
def merge_new_bg(image, background, alpha):
image = image.convert('RGB')
bg = background.convert('RGB')
alpha = alpha.convert('L')
image = F.to_tensor(image)
bg = F.to_tensor(bg)
bg = F.resize(bg, image.shape[-2:])
alpha = F.to_tensor(alpha)
new_image = image * alpha + bg * (1 - alpha)
new_image = new_image.squeeze(0).permute(1, 2, 0).numpy()
return new_image
# Merge with the new background
new_image = merge_new_bg(image, background, prediction)
plt.figure(figsize=(7, 7))
plt.imshow(new_image)
plt.show()
Find the entire code here and don’t forget to follow my GitHub. This is a powerful addition to image matting, making it easier to accurately estimate foreground objects in images and videos. Video conferencing like ZOOM can use this technology to effectively remove backgrounds effectively.
Conclusion
ViTMatte is a groundbreaking addition to the world of image matting, making it easier than ever to accurately estimate foreground objects in images and videos. With the ability to leverage pre-trained vision transformers, ViTMatte offers results. By following the steps outlined in this article, you can harness the capabilities of ViTMatte to better image matting and explore creative applications like background replacement. Whether you’re a developer, researcher, or curious about the latest advancements in computer vision, ViTMatte is a valuable tool to have.
Key Takeaways:
- ViTMatte is a model with plain Vision Transformers (ViTs) to excel in image matting, accurately estimating the foreground object in images and videos.
- ViTMatte incorporates a hybrid attention mechanism and a detail capture module to strike a balance between performance and computation, making it efficient and robust for image matting.
- ViTMatte has achieved state-of-the-art performance on benchmark datasets, outperforming past image matting methods by a margin.
- It inherits properties from ViTs, including pretraining strategies, architectural design, and flexible inference strategies.
Frequently Asked Questions
A1: Image matting is the process of accurately estimating the foreground object in images and videos. It’s crucial for applications, background blur in video calls, and portrait photography.
A2: ViTMatte leverages plain Vision Transformers (ViTs) and innovative attention mechanisms to achieve state-of-the-art performance and adaptability in image matting.
A3: ViTMatte’s key contributions include introducing ViTs to image matting, a hybrid attention mechanism, and a detail capture module. It inherits ViT’s strengths and achieves performance on benchmark datasets.
A4: ViTMatte was contributed by Nielsr in HuggingFace from Yao et al. (2023) and the original code can be found here(https://github.com/hustvl/ViTMatte).
A5: Image matting with ViTMatte opens up creative possibilities, background replacement, artistic effects, and video conferencing features like virtual backgrounds. Developers and researchers to explore new ways of improving images and videos.
References
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.ViTMatte: Unveiling the Cutting-Edge in Image Matting Technology

