
Introduction
In my previous blog post, Building Multi-Document Agentic RAG using LLamaIndex, I demonstrated how to create a retrieval-augmented generation (RAG) system that could handle and query across three documents using LLamaIndex. While that was a powerful start, real-world applications often require the ability to handle a larger corpus of documents.
This blog will focus on scaling that system from three documents to eleven and beyond. We’ll dive into the code, challenges of scaling, and how to build an efficient agent that can dynamically retrieve information from a larger set of sources.
Learning Objectives
- Understand scaling Multi-Document Agentic RAG system from handling a few documents to over 10+ documents using LLamaIndex.
- Learn how to build and integrate tool-based query mechanisms to enhance RAG models.
- Understand the use of VectorStoreIndex and ObjectIndex in efficiently retrieving relevant documents and tools.
- Implement a dynamic agent capable of answering complex queries by retrieving relevant papers from a large set of documents.
- Identify the challenges and best practices when scaling RAG systems to multiple documents.
This article was published as a part of the Data Science Blogathon.
Key Steps Involved
In the previous blog, I introduced the concept of Agentic RAG—an approach where we combine information retrieval with generative models to answer user queries using relevant external documents. We used LLamaIndex to build a simple, multi-document agentic RAG, which could query across three documents.
The key steps involved:
- Document Ingestion: Using SimpleDirectoryReader to load and split documents into chunks.
- Index Creation: Leveraging VectorStoreIndex for semantic search and SummaryIndex for summarization.
- Agent Setup: Integrating OpenAI’s API to answer queries by retrieving relevant chunks of information from the documents.
While this setup worked well for a small number of documents, we encountered challenges in scalability. As we expanded beyond three documents, issues like tool management, performance overhead, and slower query responses arose. This post addresses those challenges.
Key Challenges in Scaling to 10+ Documents
Scaling to 11 or more documents introduces several complexities:
Performance Considerations
Querying across multiple documents increases the computational load, especially in terms of memory usage and response times. When the system processes a larger number of documents, ensuring quick and accurate responses becomes a primary challenge.
Tool Management
Each document is paired with its own retrieval and summarization tool, meaning the system needs a robust mechanism to manage these tools efficiently.
Index Efficiency
With 11 documents, using the VectorStoreIndex becomes more complex. The larger the index, the more the system needs to sift through to find relevant information, potentially increasing query times. We’ll discuss how LLamaIndex efficiently handles these challenges with its indexing techniques.
Implementing the Code to Handle 10+ Documents
Let’s dive into the implementation to scale our Agentic RAG from three to 11 documents.
Document Collection
Here are the 11 papers we’ll be working with:
- MetaGPT
- LongLoRA
- LoFT-Q
- SWE-Bench
- SelfRAG
- Zipformer
- Values
- Finetune Fair Diffusion
- Knowledge Card
- Metra
- VR-MCL
The first step is to download the papers. Here’s the Python code to automate this:
urls = [
"https://openreview.net/pdf?id=VtmBAGCN7o",
"https://openreview.net/pdf?id=6PmJoRfdaK",
"https://openreview.net/pdf?id=LzPWWPAdY4",
"https://openreview.net/pdf?id=VTF8yNQM66",
"https://openreview.net/pdf?id=hSyW5go0v8",
"https://openreview.net/pdf?id=9WD9KwssyT",
"https://openreview.net/pdf?id=yV6fD7LYkF",
"https://openreview.net/pdf?id=hnrB5YHoYu",
"https://openreview.net/pdf?id=WbWtOYIzIK",
"https://openreview.net/pdf?id=c5pwL0Soay",
"https://openreview.net/pdf?id=TpD2aG1h0D"
]
papers = [
"metagpt.pdf",
"longlora.pdf",
"loftq.pdf",
"swebench.pdf",
"selfrag.pdf",
"zipformer.pdf",
"values.pdf",
"finetune_fair_diffusion.pdf",
"knowledge_card.pdf",
"metra.pdf",
"vr_mcl.pdf"
]
# Downloading the papers
for url, paper in zip(urls, papers):
!wget "{url}" -O "{paper}"Tool Setup
Once the documents are downloaded, the next step is to create the tools required for querying and summarizing each document.
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, SummaryIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.tools import FunctionTool, QueryEngineTool
from llama_index.core.vector_stores import MetadataFilters, FilterCondition
from typing import List, Optional
def get_doc_tools(
file_path: str,
name: str,
) -> str:
"""Get vector query and summary query tools from a document."""
# load documents
documents = SimpleDirectoryReader(input_files=[file_path]).load_data()
splitter = SentenceSplitter(chunk_size=1024)
nodes = splitter.get_nodes_from_documents(documents)
vector_index = VectorStoreIndex(nodes)
def vector_query(
query: str,
page_numbers: Optional[List[str]] = None
) -> str:
"""Use to answer questions over a given paper.
Useful if you have specific questions over the paper.
Always leave page_numbers as None UNLESS there is a specific page you want to search for.
Args:
query (str): the string query to be embedded.
page_numbers (Optional[List[str]]): Filter by set of pages. Leave as NONE
if we want to perform a vector search
over all pages. Otherwise, filter by the set of specified pages.
"""
page_numbers = page_numbers or []
metadata_dicts = [
{"key": "page_label", "value": p} for p in page_numbers
]
query_engine = vector_index.as_query_engine(
similarity_top_k=2,
filters=MetadataFilters.from_dicts(
metadata_dicts,
condition=FilterCondition.OR
)
)
response = query_engine.query(query)
return response
vector_query_tool = FunctionTool.from_defaults(
name=f"vector_tool_{name}",
fn=vector_query
)
summary_index = SummaryIndex(nodes)
summary_query_engine = summary_index.as_query_engine(
response_mode="tree_summarize",
use_async=True,
)
summary_tool = QueryEngineTool.from_defaults(
name=f"summary_tool_{name}",
query_engine=summary_query_engine,
description=(
f"Useful for summarization questions related to {name}"
),
)
return vector_query_tool, summary_toolThis function generates vector and summary query tools for each document, allowing the system to handle queries and generate summaries efficiently.
Now we will enhance agentic RAG with tool retrieval.
Building the Agent
Next, we need to extend the agent with the ability to retrieve and manage tools from all 11 documents.
from utils import get_doc_tools
from pathlib import Path
paper_to_tools_dict = {}
for paper in papers:
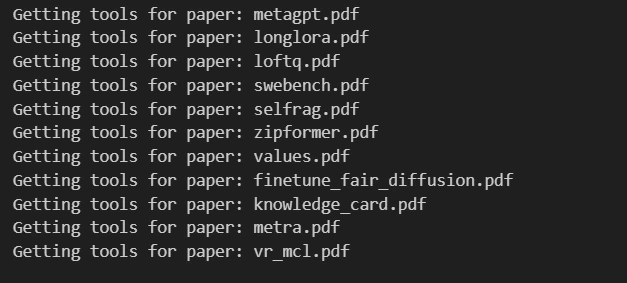
print(f"Getting tools for paper: {paper}")
vector_tool, summary_tool = get_doc_tools(paper, Path(paper).stem)
paper_to_tools_dict[paper] = [vector_tool, summary_tool]
all_tools = [t for paper in papers for t in paper_to_tools_dict[paper]]Output will look like below:
Tool Retrieval
The next step is to create an “object” index over these tools and build a retrieval system that can dynamically pull the relevant tools for a given query.
from llama_index.core import VectorStoreIndex
from llama_index.core.objects import ObjectIndex
obj_index = ObjectIndex.from_objects(
all_tools,
index_cls=VectorStoreIndex,
)
obj_retriever = obj_index.as_retriever(similarity_top_k=3)Now, the system can retrieve the most relevant tools based on the query.
Let’s see an example:
tools = obj_retriever.retrieve(
"Tell me about the eval dataset used in MetaGPT and SWE-Bench"
)
#retrieves 3 objects, lets see the 3rd one
print(tools[2].metadata)
Agent Setup
Now, we integrate the tool retriever into the agent runner, ensuring it dynamically selects the best tools to respond to each query.
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.agent import AgentRunner
agent_worker = FunctionCallingAgentWorker.from_tools(
tool_retriever=obj_retriever,
llm=llm,
system_prompt=""" \
You are an agent designed to answer queries over a set of given papers.
Please always use the tools provided to answer a question. Do not rely on prior knowledge.\
""",
verbose=True
)
agent = AgentRunner(agent_worker)Querying Across 11 Documents
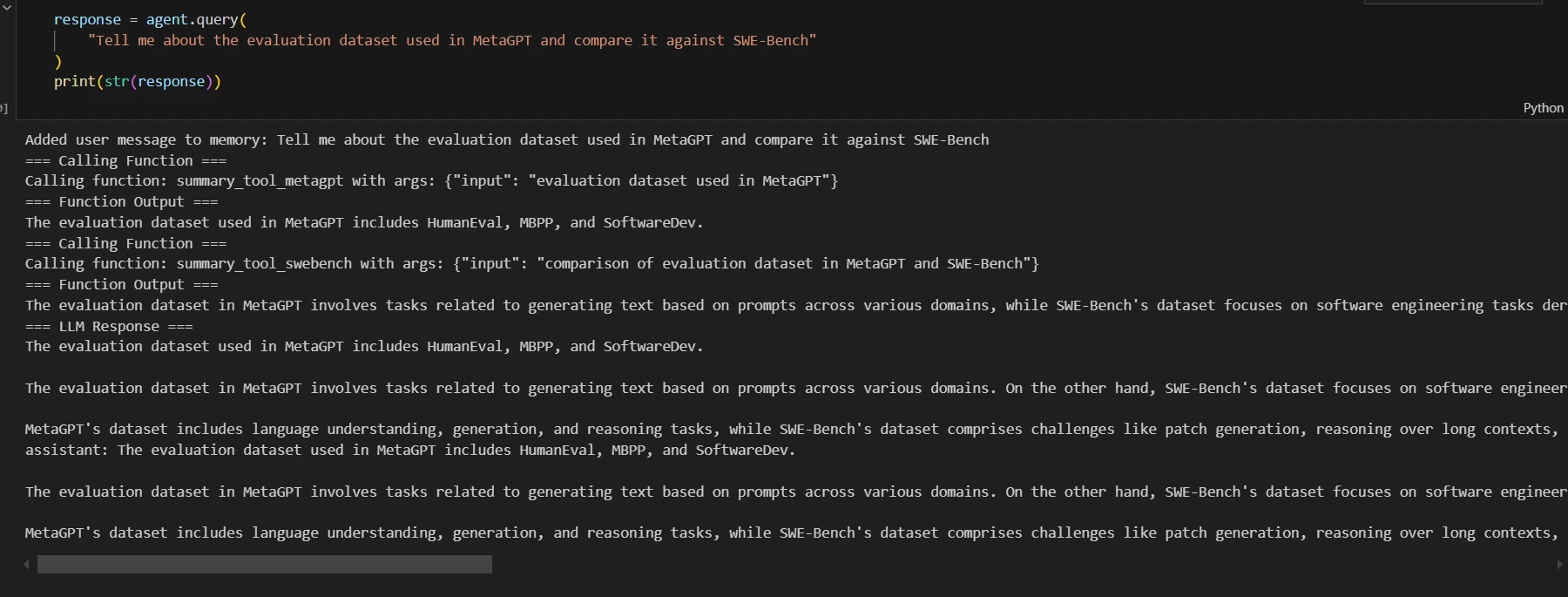
Let’s see how the system performs when querying across multiple documents. We’ll query both the MetaGPT and SWE-Bench papers to compare their evaluation datasets.
response = agent.query("Tell me about the evaluation dataset used in MetaGPT and compare it against SWE-Bench")
print(str(response))
Output:
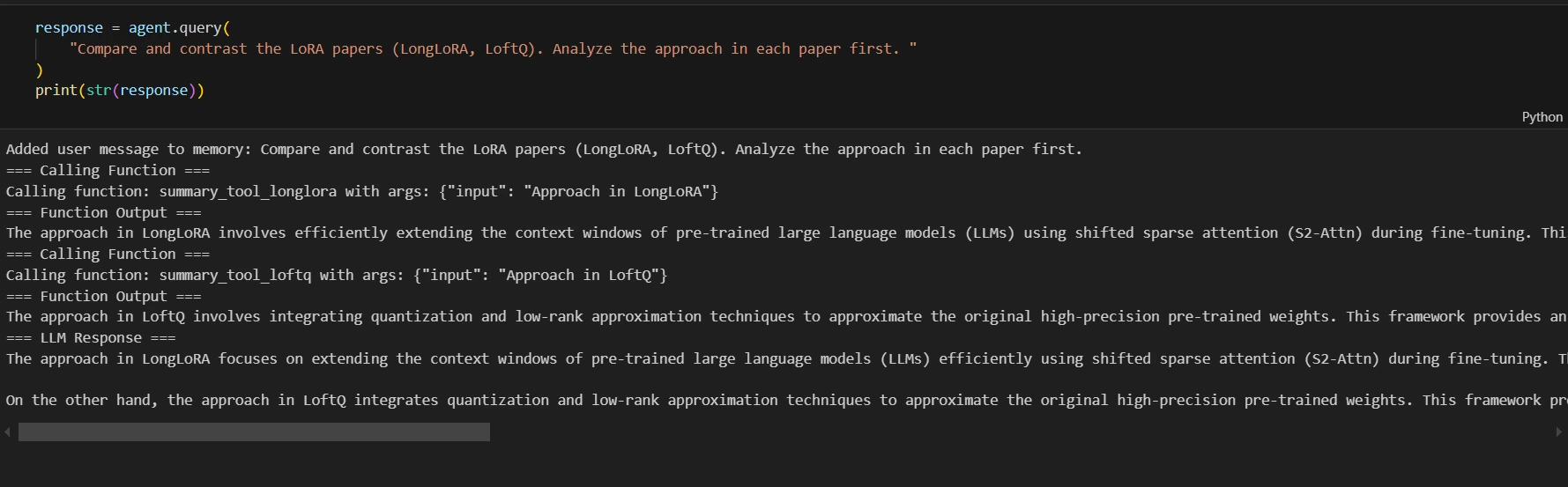
Let’s see other example
response = agent.query(
"Compare and contrast the LoRA papers (LongLoRA, LoftQ). Analyze the approach in each paper first. "
)
print(str(response))
Output:
Results and Performance Insights
We will now explore the results and performance insights below:
Performance Metrics
When scaling to 11 documents, the performance remained robust, but we observed an increase in query times by approximately 15-20% compared to the 3-document setup. The overall retrieval accuracy, however, stayed consistent.
Scalability Analysis
The system is highly scalable thanks to LLamaIndex’s efficient chunking and indexing. By carefully managing the tools, we were able to handle 11 documents with minimal overhead. This approach can be expanded to support even more documents, allowing further growth in real-world applications.
Conclusion
Scaling from three to 11+ documents is a significant milestone in building a robust RAG system. This approach leverages LLamaIndex to manage large sets of documents while maintaining the system’s performance and responsiveness.
I encourage you to try scaling your own retrieval-augmented generation systems using LLamaIndex and share your results. Feel free to check out my previous blog here to get started!
Key Takeaways
- It’s possible to scale a Retrieval-Augmented Generation (RAG) system to handle more documents using efficient indexing methods like VectorStoreIndex and ObjectIndex.
- By assigning specific tools to documents (vector search, summary tools), agents can leverage specialized methods for retrieving information, improving response accuracy.
- Using the AgentRunner with tool retrieval allows agents to intelligently select and apply the right tools based on the query, making the system more flexible and adaptive.
- Even when dealing with a large number of documents, RAG systems can maintain responsiveness and accuracy by retrieving and applying tools dynamically, rather than brute-force searching all content.
- Optimizing chunking, tool assignment, and indexing strategies are crucial when scaling RAG systems to ensure performance and accuracy.
Frequently Asked Questions
A. Handling 3 documents requires simpler indexing and retrieval processes. As the number of documents increases (e.g., to 10+), you need more sophisticated retrieval mechanisms like ObjectIndex and tool retrieval to maintain performance and accuracy.
A. VectorStoreIndex helps in efficient retrieval of document chunks based on similarity, while ObjectIndex allows you to store and retrieve tools associated with different documents. Together, they help in managing large-scale document sets effectively.
A. Tool-based retrieval enables the system to apply specialized tools (e.g., vector search or summarization) to each document, improving the accuracy of answers and reducing computation time compared to treating all documents the same way.
A. To handle more documents, you can optimize the retrieval process by fine-tuning the indexing, using distributed computing techniques, and potentially introducing more advanced filtering mechanisms to narrow down the document set before applying tools.
A. Scaling Multi-Document Agentic RAG systems effectively involves optimizing data retrieval methods, implementing efficient indexing strategies, and leveraging advanced language models to enhance query accuracy. Utilizing tools like LLamaIndex can significantly improve the system’s performance by facilitating better management of multiple documents and ensuring timely access to relevant information.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hey everyone, Ketan here! I’m a Data Scientist at Syngene International Limited. I have completed my Master’s in Data Science from VIT AP and I have a burning passion for Generative AI. My expertise lies in crafting machine learning models and wielding Natural Language Processing for innovative projects. Currently, I’m putting this knowledge to work in drug discovery research at Syngene, exploring the potential of LLMs. Always eager to connect and delve deeper into the ever-evolving world of data science!

