
Introduction
In the field of machine learning, developing robust and accurate predictive models is a primary objective. Ensemble learning techniques excel at enhancing model performance, with bagging, short for bootstrap aggregating, playing a crucial role in reducing variance and improving model stability. This article explores bagging, explaining its concepts, applications, and nuances, and demonstrates how it utilizes multiple models to improve prediction accuracy and reliability.
Overview
- Understand the fundamental concept of Bagging and its purpose in reducing variance and enhancing model stability.
- Describe the steps involved in putting Bagging into practice, such as preparing the dataset, bootstrapping, training the model, generating predictions, and merging predictions.
- Acknowledge the many benefits of bagging, including its ability to reduce variation, mitigate overfitting, remain resilient in the face of outliers, and be applied to a variety of machine learning problems.
- Gain practical experience by implementing Bagging for a classification task using the Wine dataset in Python, utilizing the scikit-learn library to create and evaluate a BaggingClassifier.
What is Bagging?
Bagging is a machine learning ensemble method aimed at improving the reliability and accuracy of predictive models. It involves generating several subsets of the training data using random sampling with replacement. These subsets are then used to train multiple base models, such as decision trees or neural networks.
When making predictions, the outputs from these base models are combined, often through averaging (for regression) or voting (for classification), to produce the final prediction. Bagging reduces overfitting by creating diversity among the models and enhances overall performance by lowering variance and increasing robustness.

Implementation Steps of Bagging
Here’s a general outline of implementing Bagging:
- Dataset Preparation: Clean and preprocess your dataset. Split it into training and test sets.
- Bootstrap Sampling: Randomly sample from the training data with replacement to create multiple bootstrap samples. Each sample typically has the same size as the original dataset.
- Model Training: Train a base model (e.g., decision tree, neural network) on each bootstrap sample. Each model is trained independently.
- Prediction Generation: Use each trained model to predict the test data.
- Combining Predictions: Aggregate the predictions from all models using methods like majority voting for classification or averaging for regression.
- Evaluation: Assess the ensemble’s performance on the test data using metrics like accuracy, F1 score, or mean squared error.
- Hyperparameter Tuning: Adjust the hyperparameters of the base models or the ensemble as needed, using techniques like cross-validation.
- Deployment: Once satisfied with the ensemble’s performance, deploy it to make predictions on new data.
Also Read: Top 10 Machine Learning Algorithms to Use in 2024
Understanding Ensemble Learning
To increase performance overall, ensemble learning integrates the predictions of several models. By combining the insights from multiple models, this method frequently produces forecasts that are more accurate than those of any one model alone.
Popular ensemble methods include:
- Bagging: Involves training multiple base models on different subsets of the training data created through random sampling with replacement.
- Boosting: A sequential method where each model focuses on correcting the errors of its predecessors, with popular algorithms like AdaBoost and XGBoost.
- Random Forest: An ensemble of decision trees, each trained on a random subset of features and data, with final predictions made by aggregating individual tree predictions.
- Stacking: Combines the predictions of multiple base models using a meta-learner to produce the final prediction.
Benefits of Bagging
- Variance Reduction: By training multiple models on different data subsets, Bagging reduces variance, leading to more stable and reliable predictions.
- Overfitting Mitigation: The diversity among base models helps the ensemble generalize better to new data.
- Robustness to Outliers: Aggregating multiple models’ predictions reduces the impact of outliers and noisy data points.
- Parallel Training: Training individual models can be parallelized, speeding up the process, especially with large datasets or complex models.
- Versatility: Bagging can be applied to various base learners, making it a flexible technique.
- Simplicity: The concept of random sampling with replacement and combining predictions is easy to understand and implement.
Applications of Bagging
Bagging, also known as Bootstrap Aggregating, is a versatile technique used across many areas of machine learning. Here’s a look at how it helps in various tasks:
- Classification: Bagging combines predictions from multiple classifiers trained on different data splits, making the overall results more accurate and reliable.
- Regression: In regression problems, bagging helps by averaging the outputs of multiple regressors, leading to smoother and more accurate predictions.
- Anomaly Detection: By training multiple models on different data subsets, bagging improves how well anomalies are spotted, making it more resistant to noise and outliers.
- Feature Selection: Bagging can help identify the most important features by training models on different feature subsets. This reduces overfitting and improves model performance.
- Imbalanced Data: In classification problems with uneven class distributions, bagging helps balance the classes within each data subset. This leads to better predictions for less frequent classes.
- Building Powerful Ensembles: Bagging is a core part of complex ensemble methods like Random Forests and Stacking. It trains diverse models on different data subsets to achieve better overall performance.
- Time-Series Forecasting: Bagging improves the accuracy and stability of time-series forecasts by training on various historical data splits, capturing a wider range of patterns and trends.
- Clustering: Bagging helps find more reliable clusters, especially in noisy or high-dimensional data. This is achieved by training multiple models on different data subsets and identifying consistent clusters across them.
Bagging in Python: A Brief Tutorial
Let us now explore tutorial on bagging in Python.
# Importing necessary libraries
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=42)
# Initialize the base classifier (in this case, a decision tree)
base_classifier = DecisionTreeClassifier()
# Initialize the BaggingClassifier
bagging_classifier = BaggingClassifier(base_estimator=base_classifier,
n_estimators=10, random_state=42)
# Train the BaggingClassifier
bagging_classifier.fit(X_train, y_train)
# Make predictions on the test set
y_pred = bagging_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
This example demonstrates how to use the BaggingClassifier from scikit-learn to perform Bagging for classification tasks using the Wine dataset.
Differences Between Bagging and Boosting
Let us now explore difference between bagging and boosting.
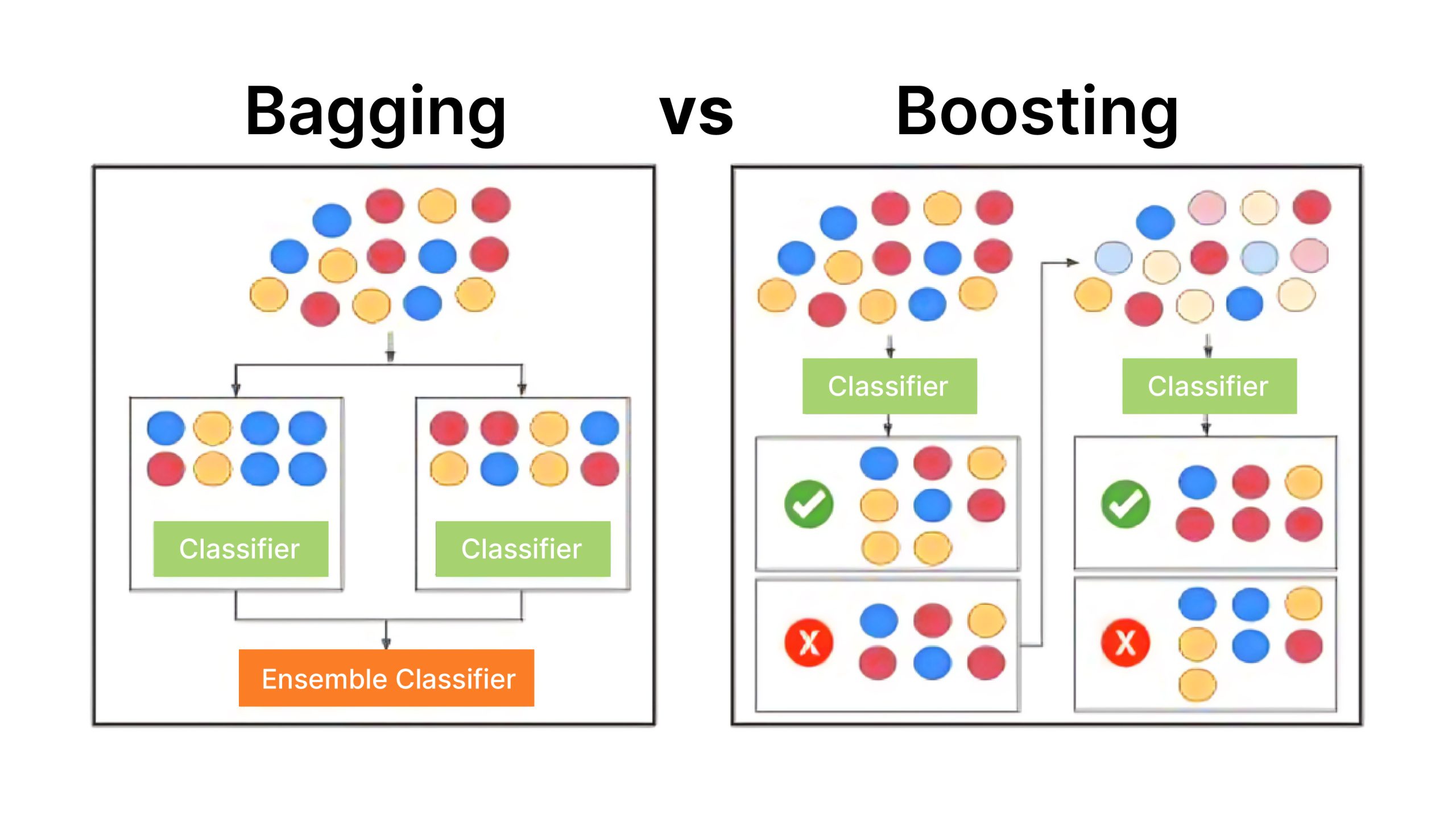
| Feature | Bagging | Boosting |
| Type of Ensemble | Parallel ensemble method | Sequential ensemble method |
| Base Learners | Trained in parallel on different subsets of the data | Trained sequentially, correcting previous mistakes |
| Weighting of Data | All data points equally weighted | Misclassified points given more weight |
| Reduction of Bias/Variance | Mainly reduces variance | Mainly reduces bias |
| Handling of Outliers | Resilient to outliers | More sensitive to outliers |
| Robustness | Generally robust | Less robust to outliers |
| Model Training Time | Can be parallelized | Generally slower due to sequential training |
| Examples | Random Forest | AdaBoost, Gradient Boosting, XGBoost |
Conclusion
Bagging is a powerful yet simple ensemble method that strengthens model performance by lowering variation, enhancing generalization, and increasing resilience. Its ease of use and ability to train models in parallel make it popular across various applications.
Frequently Asked Questions
A. Bagging in machine learning reduces variance by introducing diversity among the base models. Each model is trained on a different subset of the data, and when their predictions are combined, errors tend to cancel out. This leads to more stable and reliable predictions.
A. Bagging can be computationally intensive because it involves training multiple models. However, the training of individual models can be parallelized, which can mitigate some of the computational costs.
A. Bagging and Boosting are both ensemble methods but uses different approach. Bagging trains base models in parallel on different data subsets and combines their predictions to reduce variance. Boosting trains base models sequentially, with each model focusing on correcting the mistakes of its predecessors, aiming to reduce bias.

