
RAG is a sophisticated AI technique that enhances the performance of LLMs by retrieving relevant documents or information from external sources during text generation; unlike traditional LLMs that rely solely on internal training data, RAG leverages real-time information to deliver more accurate and contextually relevant responses. While Naive RAG works very well for simple queries, it struggles with complex questions requiring multi-step reasoning or iterative refinement.
Learning Objectives
- Understand the key differences between Agentic RAG and Naive RAG.
- Recognize the limitations of Naive RAG in handling complex queries.
- Explore diverse use cases where Agentic RAG excels in multi-step reasoning tasks.
- Learn how to implement Agentic RAG in Python using CrewAI for intelligent data retrieval and summarization.
- Discover how Agentic RAG strengthens Naive RAG’s capabilities by adding decision-making agents.
This article was published as a part of the Data Science Blogathon.
Agentic RAG Strengthening Capabilities of Naive RAG
Agentic RAG is a novel hybrid approach that merges the strengths of Retrieval-Augmented Generation and AI Agents. This framework enhances generation and decision-making by integrating dynamic retrieval systems (RAG) with autonomous agents. In Agentic RAG, the retriever and generator are combined and operate within a multi-agent framework where agents can request specific pieces of information and make decisions based on retrieved data.
Agentic RAG vs Naive RAG
- While Naive RAG focuses solely on improving generation through information retrieval, Agentic RAG adds a layer of decision-making through autonomous agents.
- In Naive RAG, the retriever is passive, retrieving data only when requested. In contrast, Agentic RAG employs agents that actively decide when, how, and what to retrieve.
Top k retrieval in Naive RAG can fail in the following scenarios:
- Summarization Questions: “Give me a summary of this document”.
- Comparison Questions: “Compare business strategy of PepsiCo vs Coca Cola for the last quarter of 2023”
- Multi-part Complex Queries: “Tell me about the top arguments on Retail Inflation presented in the Mint Article and tell me about the top arguments on Retail inflation on Economic Times Article. Make a comparison table based on the collected arguments and then generate the top conclusions based on these facts.”

Use Cases of Agentic RAG
With the incorporation of AI agents in RAG, agentic RAG could be leveraged in several intelligent, multi-step reasoning systems. Few key use cases could be the following –
- Legal Research: Comparison of Legal Documents and Generation of Key Clauses for quick decision making.
- Market Analysis: Competitive analysis of Top brands in a product segment.
- Medical Diagnosis: Comparison of Patient Data and Latest Research Studies to generate possible diagnosis.
- Financial Analysis: Processing Different Financial Reports and generation of key points for better investment insights.
- Compliance: Ensuring regulatory compliance by comparing policies with laws.
Building Agentic RAG with Python and CrewAI
Consider a dataset consisting of different tech products and the customer issues raised for these products as shown in the image below. You can download the dataset from here.
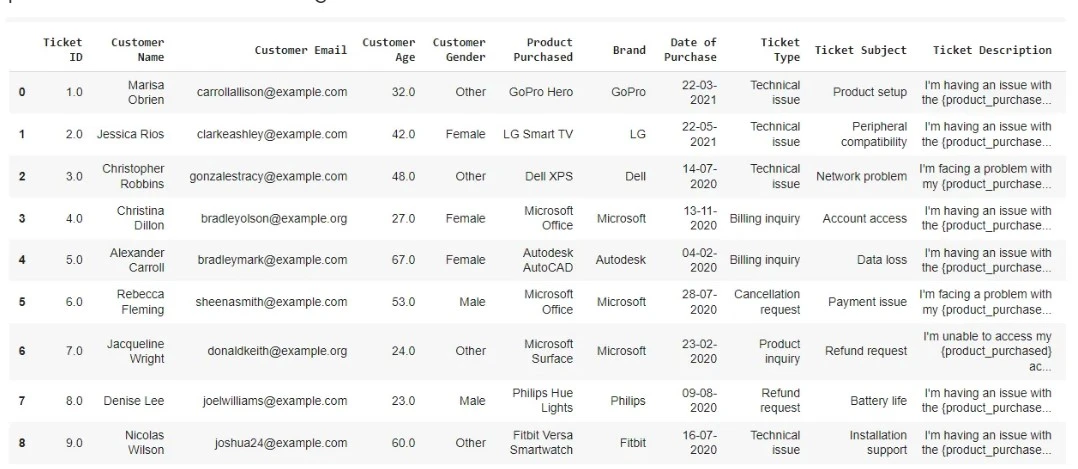
We can develop an agentic RAG system to summarize the top customer complaints for each of the brands like GoPro, Microsoft etc across all their products. We will see in the following steps how we can achieve it.
Step1: Install Necessary Python Libraries
Before starting with Agentic RAG, it’s crucial to install the required Python libraries, including CrewAI and LlamaIndex, to support data retrieval and agent-based tasks.
!pip install llama-index-core
!pip install llama-index-readers-file
!pip install llama-index-embeddings-openai
!pip install llama-index-llms-llama-api
!pip install 'crewai[tools]'Step2: Import the required Python Libraries
This step involves importing essential libraries to set up the agents and tools for implementing Agentic RAG, enabling efficient data processing and retrieval.
import os
from crewai import Agent, Task, Crew, Process
from crewai_tools import LlamaIndexTool
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.llms.openai import OpenAIStep3: Read the relevant csv file of Customer Issues Data
Now we load the dataset containing customer issues to make it accessible for analysis, forming the basis for retrieval and summarization.
reader = SimpleDirectoryReader(input_files=["CustomerSuppTicket_small.csv"])
docs = reader.load_data()Step4: Define the Open AI API key
This step sets up the OpenAI API key, which is necessary to access OpenAI’s language models for handling data queries.
from google.colab import userdata
openai_api_key = ''
os.environ['OPENAI_API_KEY']=openai_api_keyStep5: LLM Initialization
Initialize the Large Language Model (LLM), which will process the query results retrieved by the Agentic RAG system, enhancing summarization and insights.
llm = OpenAI(model="gpt-4o")Step6: Creating a Vector Store Index and Query Engine
This involves creating a vector store index and query engine, making the dataset easily searchable based on similarity, with refined results delivered by the LLM.
#creates a VectorStoreIndex from a list of documents (docs)
index = VectorStoreIndex.from_documents(docs)
#The vector store is transformed into a query engine.
#Setting similarity_top_k=5 limits the results to the top 5 documents that are most similar to the query,
#llm specifies that the LLM should be used to process and refine the query results
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)Step7: Creating a Tool Based on the Defined Query Engine
This uses LlamaIndexTool to create a tool based on the query_engine. The tool is named “Customer Support Query Tool” and is described as a way to look up customer ticket data.
query_tool = LlamaIndexTool.from_query_engine(
query_engine,
name="Customer Support Query Tool",
description="Use this tool to lookup the customer ticket data",
)Step8: Defining the Agents
Agents are defined with specific roles and goals to perform tasks, such as data analysis and content creation, aimed at uncovering insights from customer data.
researcher = Agent(
role="Customer Ticket Analyst",
goal="Uncover insights about customer issues trends",
backstory="""You work at a Product Company.
Your goal is to understand customer issues patterns for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
verbose=True,
allow_delegation=False,
tools=[query_tool],
)
writer = Agent(
role="Product Content Specialist",
goal="""Craft compelling content on customer issues trends for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
backstory="""You are a renowned Content Specialist, known for your insightful and engaging articles.
You transform complex sales data into compelling narratives.""",
verbose=True,
allow_delegation=False,
)The role of the ‘researcher’ agent is an analyst who will review and interpret customer support data. The goal of this agent is defined to “uncover insights about customer issues trends. The backstory provides the agent with a background or context about its purpose. Here, it assumes the role of a support analyst at a product company tasked with understanding customer issues for various brands (e.g., GoPro, LG, Dell, etc.). This background helps the agent focus on each brand individually as it looks for trends. The agent is provided with the tool – ‘query_tool’. This means that the researcher agent can use this tool to retrieve relevant customer support data, which it can then analyze according to its goal and backstory.
The role of the ‘writer’ agent is that of a content creator focused on providing product insights. The goal of this agent is defined to to “craft compelling content” regarding trends in customer issues for a list of brands. This goal will guide the agent to look specifically for insights that would make good narrative or analytical content. The backstory gives the agent additional context, painting it as a highly skilled content creator capable of turning data into engaging articles.
Step9: Creating the Tasks for the Defined Agents
Tasks are assigned to agents based on their roles, outlining specific responsibilities like data analysis and crafting narratives on customer issues.
task1 = Task(
description="""Analyze the top customer issues issues for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
expected_output="Detailed Customer Issues mentioning NAME of Brand report with trends and insights",
agent=researcher,
)
task2 = Task(
description="""Using the insights provided, develop an engaging blog
post that highlights the top-customer issues for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone' and their pain points.
Your post should be informative yet accessible, catering to a casual audience.Ensure thet the post has NAME of the BRAND e.g. GoPro, FitBit etc.
Make it sound cool, avoid complex words.""",
expected_output="Full blog post in Bullet Points of customer issues. Ensure thet the Blog has NAME of the BRAND e.g. GoPro, FitBit etc.",
agent=writer,
)Step10: Instantiating the Crew with a Sequential Process
A crew is formed with agents and tasks, and this step initiates the process, where agents collaboratively retrieve, analyze, and present data insights.
crew = Crew(
agents=[researcher,writer],
tasks=[task1,task2],
verbose=True, # You can set it to 1 or 2 to different logging levels
)
result = crew.kickoff()This code creates a Crew instance, which is a group of agents assigned specific tasks, and then initiates the crew’s work with the kickoff() method.
agents: This parameter assigns a list of agents to the crew. Here, we have two agents: researcher and writer. Each agent has a specific role—researcher focuses on analyzing the customer issues for each brands, while writer focuses on summarizing them.
tasks: This parameter provides a list of tasks that the crew should complete.
Output

As can be seen from the output above, using the Agentic RAG system, a concise summary in bullet points of all customer issues across different brands like LG, Dell, Fitbit etc have been generated. This concise and accurate summarization of customer issues across the different brands is possible only through use of the agents.
Conclusion
Agentic RAG is a major step forward in Retrieval-Augmented Generation. It blends RAG’s retrieval power with autonomous agents’ decision-making ability. This hybrid model goes beyond Naive RAG, tackling complex questions and comparative analysis. Across industries, it provides more insightful, accurate responses. Using Python and CrewAI, developers can now create Agentic RAG systems for smarter, data-driven decisions.
Key Takeaways
- Agentic RAG integrates autonomous agents, adding a layer of dynamic decision-making that goes beyond simple retrieval.
- Agentic RAG leverages agents to tackle complex queries, including summarization, comparison, and multi-part reasoning. This capability addresses limitations where Naive RAG typically falls short.
- Agentic RAG is valuable in fields like legal research, medical diagnosis, financial analysis, and compliance monitoring. It provides nuanced insights and enhanced decision-making support.
- Using CrewAI, Agentic RAG can be effectively implemented in Python, demonstrating a structured approach for multi-agent collaboration to tackle intricate customer support analysis tasks.
- Agentic RAG’s flexible agent-based architecture makes it well-suited to complex data retrieval and analysis in diverse use cases, from customer service to advanced analytics.
Frequently Asked Questions
A. Agentic RAG incorporates autonomous agents that actively manage data retrieval and decision-making, while Naive RAG simply retrieves information on request without additional reasoning capabilities.
A. Naive RAG’s passive retrieval approach is limited to direct responses, which makes it ineffective for summarization, comparison, or multi-part queries that need iterative reasoning or layered information retrieval.
A. Agentic RAG is valuable for tasks that require multi-step reasoning, such as legal research, market analysis, medical diagnosis, financial insights, and ensuring compliance through policy comparison.
A. Yes, you can implement Agentic RAG in Python, particularly using libraries like CrewAI. This helps set up and manage agents that collaborate to retrieve, analyze, and summarize data.
A. Industries with complex data processing needs, such as law, healthcare, finance, and customer support, stand to benefit the most from Agentic RAG’s intelligent data retrieval and decision-making capabilities.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.

