
Introduction
At the Google I/O event, we saw many updates and new projects. One of the projects that caught my attention is Peligemma. A versatile and lightweight vision-language model (VLM) inspired by PaLI-3 and based on open components such as the SigLIP vision model and the Gemma language model.
PaliGemma is released in three types of models: pretrained (pt) models, mix models, and fine-tuned (ft) models, each available in various resolutions and precisions. The models are intended for research purposes and are equipped with transformers integration.
PaliGemma’s capabilities include image captioning, visual question answering, entity detection, and referring expression segmentation, making it suitable for a range of vision-language tasks. The model is not designed for conversational use but can be fine-tuned for specific use cases. PaliGemma represents a significant advancement in vision-language models and has the potential to revolutionize how technology interacts with human language.

Understanding PaliGemma
PaliGemma, a state-of-the-art vision-language model developed by Google, combines image and text processing capabilities to generate text outputs. The combined PaliGemma model is pre-trained on image-text data and can process and generate human-like language with an incredible understanding of context and nuance.
Under the Hood
The architecture of PaliGemma consists of SigLIP-So400m as the image encoder and Gemma-2B as the text decoder. SigLIP is a state-of-the-art model that can understand both images and text and is trained jointly. Similar to PaLI-3, the combined PaliGemma model is pre-trained on image-text data. The input text is tokenized normally, and a <bos> token is added at the beginning, and an additional newline token (\n) is appended. The tokenized text is also prefixed with a fixed number of <image> tokens. The model uses full block attention for the complete input (image + bos + prompt + \n), and a causal attention mask for the generated text.
Model Options for Every Need
The team at Google has released three types of PaliGemma models: the pretrained (pt) models, the mix models, and the fine-tuned (ft) models, each with different resolutions and available in multiple precisions for convenience. The pretrained models are designed to be fine-tuned on downstream tasks, such as captioning or referring segmentation. The mix models are pretrained models fine-tuned to a mixture of tasks, suitable for general-purpose inference with free-text prompts and research purposes only. The fine-tuned models can be configured to solve specific tasks by conditioning them with task prefixes, such as “detect” or “segment.” PaliGemma is a single-turn vision language model not meant for conversational use, and it works best when fine-tuned to a specific use case.
Also read: The Omniscient GPT-4o + ChatGPT is HERE!
PaliGemma’s Superpowers
PaliGemma’s capabilities span a wide range of vision-language tasks, making it a versatile and powerful model in natural language processing and computer vision.
From Image Captioning to Q&A
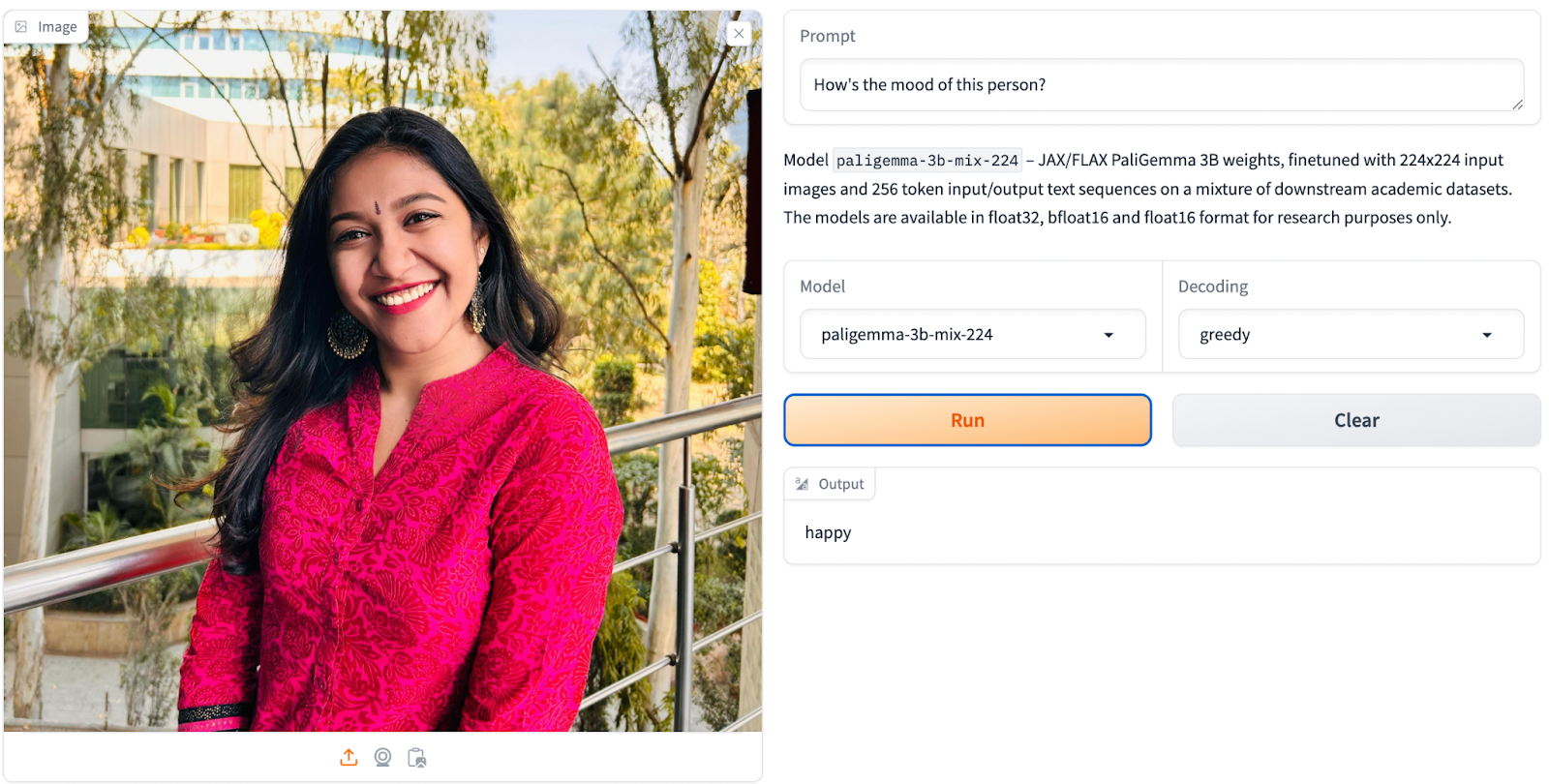
PaliGemma is equipped with the ability to caption images when prompted to do so. It can generate descriptive text based on the content of an image, providing valuable insights into its visual content. Additionally, PaliGemma can answer questions about an image, demonstrating its proficiency in visual question-answering tasks. By passing a question along with an image, PaliGemma can provide relevant and accurate answers, showcasing its understanding of visual and textual information.
Prompt: “How’s the mood of this person?”
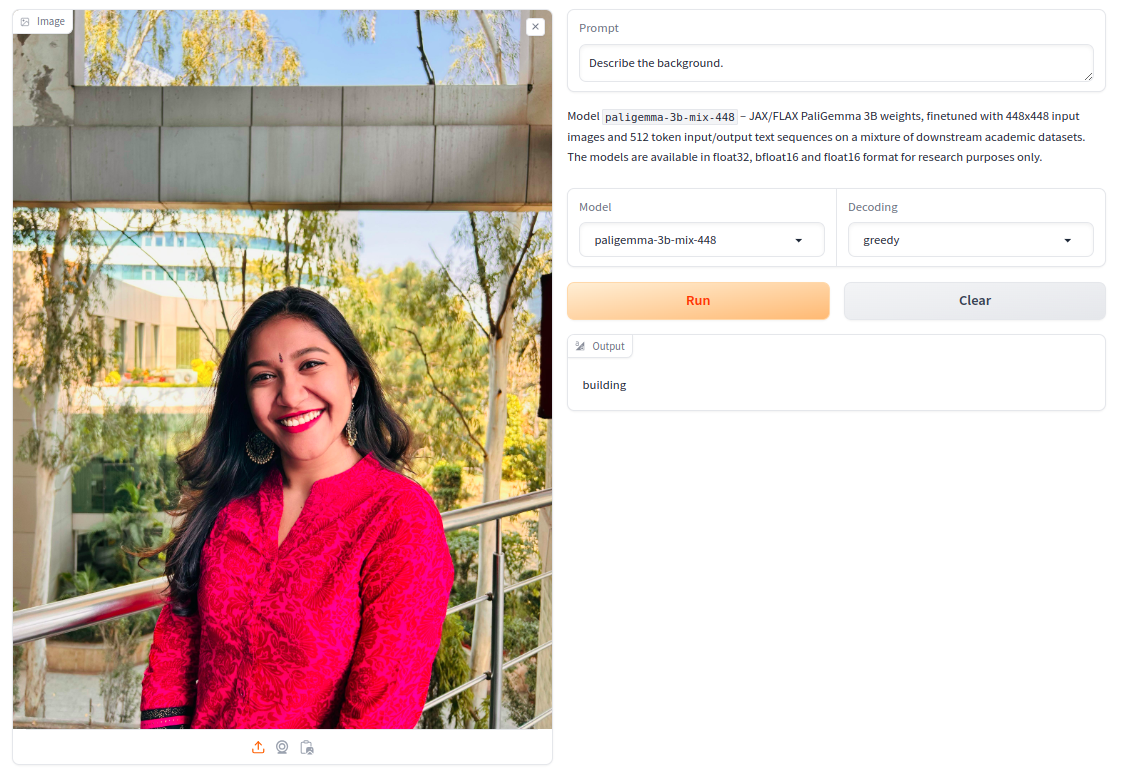
Prompt: “Describe the background”
The Power of Mix Models
The mix models of PaliGemma have been fine-tuned on a mixture of tasks, making them suitable for general-purpose inference with free-text prompts and research purposes. These models are designed to be transferred (by fine-tuning) to specific tasks using a similar prompt structure. They offer great document understanding and reasoning capabilities, making them valuable for vision-language tasks. The mix models are particularly useful for interactive testing, allowing users to explore and unlock the full potential of PaliGemma’s capabilities. By leveraging the mix models, users can experiment with various captioning prompts and visual question-answering tasks to understand how PaliGemma responds to different inputs and prompts.
PaliGemma’s mix models are not designed for conversational use but can be fine-tuned to specific use cases. They can be configured to solve specific tasks by conditioning them with task prefixes, such as “detect” or “segment.” The mix models are part of the three models released by the Google team, including the pretrained (pt) models and the fine-tuned (ft) models, each offering different resolutions and available in multiple precisions for convenience. These models have been trained to imbue them with a rich set of capabilities, including question-answering, captioning, segmentation, and more, making them versatile tools for various vision-language tasks.
Also read: How do we use GPT 4o API for Vision, Text, Image, and more?
Putting PaliGemma to Work
PaliGemma, Google’s cutting-edge vision-language model, offers a range of capabilities and can be utilized for various tasks, including image captioning, visual question answering, and document understanding.
Running Inference with PaliGemma (Transformers & Beyond)
To run an inference with PaliGemma, the PaliGemmaForConditionalGeneration class can be used with any of the released models. The input text is tokenized normally, and a <bos> token is added at the beginning, along with an additional newline token (\n). The tokenized text is also prefixed with a fixed number of <image> tokens. The model uses full block attention for the complete input (image + bos + prompt + \n) and a causal attention mask for the generated text. The processor and model classes automatically take care of these details, allowing for inference using the familiar high-level transformers API.
Fine-Tuning PaliGemma for Your Needs
Fine-tuning PaliGemma is straightforward, thanks to transformers. The model can be easily fine-tuned on downstream tasks, such as captioning or referring segmentation. The release includes three models: pretrained (pt) models, mix models, and fine-tuned (ft) models, each with different resolutions and available in multiple precisions for convenience. The mix models, fine-tuned on various tasks, are suitable for general-purpose inference with free-text prompts and research purposes. The fine-tuned models can be configured to solve specific tasks by conditioning them with task prefixes, such as “detect” or “segment.” PaliGemma is a single-turn vision language model not meant for conversational use, and it works best when fine-tuned to a specific use case. The big_vision codebase was used to train PaliGemma, making it part of a lineage of advanced models developed by Google.
Also read: GPT-4o vs Gemini: Comparing Two Powerful Multimodal AI Models
Conclusion
The release of PaliGemma marks a significant advancement in vision-language models, offering a powerful tool for researchers and developers. With its ability to understand images and text jointly, PaliGemma provides a versatile solution for a wide range of vision-language tasks. The model’s architecture, consisting of SigLIP-So400m as the image encoder and Gemma-2B as the text decoder, enables it to process and generate human-like language with a deep understanding of context and nuance. The availability of pretrained (pt) models, mix models, and fine-tuned (ft) models, each with different resolutions and precisions, offers flexibility and convenience for various use cases. PaliGemma’s potential applications in image captioning, visual question answering, document understanding, and more make it a valuable asset for advancing research and development in the AI community.
I hope you find this article informative. If you have any suggestions or feedback, comment below. For more articles like this, explore our blog section.

