
Introduction
Running Large Language Models (LLMs) locally on your computer offers a convenient and privacy-preserving solution for accessing powerful AI capabilities without relying on cloud-based services. In this guide, we explore several methods for setting up and running LLMs directly on your machine. From web-based interfaces to desktop applications, these solutions empower users to harness the full potential of LLMs while maintaining control over their data and computing resources. Let’s delve into the options available for running LLMs locally and discover how you can bring cutting-edge AI technologies to your fingertips with ease.
Using Text generation web UI
The Text Generation Web UI utilizes Gradio as its foundation, offering seamless integration with powerful Large Language Models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA. This interface empowers users with a user-friendly platform to engage with these models and effortlessly generate text. Boasting features such as model switching, notebook mode, chat mode, and beyond, the project strives to establish itself as the premier choice for text generation via web interfaces. Its functionality closely resembles that of AUTOMATIC1111/stable-diffusion-webui, setting a high standard for accessibility and ease of use.
Features of Text generation web UI
- 3 interface modes: default (two columns), notebook, and chat.
- Dropdown menu for quickly switching between different models.
- Large number of extensions (built-in and user-contributed), including Coqui TTS for realistic voice outputs, Whisper STT for voice inputs, translation, multimodal pipelines, vector databases, Stable Diffusion integration, and a lot more. See the wiki and the extensions directory for details.
- Chat with custom characters.
- Precise chat templates for instruction-following models, including Llama-2-chat, Alpaca, Vicuna, Mistral.
- LoRA: train new LoRAs with your own data, load/unload LoRAs on the fly for generation.
- Transformers library integration: load models in 4-bit or 8-bit precision through bitsandbytes, use llama.cpp with transformers samplers (
llamacpp_HFloader), CPU inference in 32-bit precision using PyTorch. - OpenAI-compatible API server with Chat and Completions endpoints — see the examples.
How to Run?
- Clone or download the repository.
- Run the
start_linux.sh,start_windows.bat,start_macos.sh, orstart_wsl.batscript depending on your OS. - Select your GPU vendor when asked.
- Once the installation ends, browse to
http://localhost:7860/?__theme=dark.
To restart the web UI in the future, just run the start_ script again. This script creates an installer_files folder where it sets up the project’s requirements. In case you need to reinstall the requirements, you can simply delete that folder and start the web UI again.
The script accepts command-line flags. Alternatively, you can edit the CMD_FLAGS.txt file with a text editor and add your flags there.
To get updates in the future, run update_wizard_linux.sh, update_wizard_windows.bat, update_wizard_macos.sh, or update_wizard_wsl.bat.
Using chatbot-ui
Chatbot UI is an open-source platform designed to facilitate interactions with artificial intelligence chatbots. It provides users with an intuitive interface for engaging in natural language conversations with various AI models.
Features
Here’s an overview of its features:
- Chatbot UI offers a clean and user-friendly interface, making it easy for users to interact with chatbots.
- The platform supports integration with multiple AI models, including LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA, offering users a diverse range of options for generating text.
- Users can switch between different chat modes, such as notebook mode for structured conversations or chat mode for casual interactions, catering to different use cases and preferences.
- Chatbot UI provides users with customization options, allowing them to personalize their chat experience by adjusting settings such as model parameters and conversation style.
- The platform is actively maintained and regularly updated with new features and improvements, ensuring a seamless user experience and keeping pace with advancements in AI technology.
- Users have the flexibility to deploy Chatbot UI locally or host it in the cloud, providing options to suit different deployment preferences and technical requirements.
- Chatbot UI integrates with Supabase for backend storage and authentication, offering a secure and scalable solution for managing user data and session information.
How to Run?
Follow these steps to get your own Chatbot UI instance running locally.
You can watch the full video tutorial here.
- Clone the Repo- link
- Install Dependencies- Open a terminal in the root directory of your local Chatbot UI repository and run:npm install
- Install Supabase & Run Locally
Why Supabase?
Previously, we used local browser storage to store data. However, this was not a good solution for a few reasons:
- Security issues
- Limited storage
- Limits multi-modal use cases
We now use Supabase because it’s easy to use, it’s open-source, it’s Postgres, and it has a free tier for hosted instances.

Using open-webui
Open WebUI is a versatile, extensible, and user-friendly self-hosted WebUI designed to operate entirely offline. It offers robust support for various Large Language Model (LLM) runners, including Ollama and OpenAI-compatible APIs.
Features
- Open WebUI offers an intuitive chat interface inspired by ChatGPT, ensuring a user-friendly experience for effortless interactions with AI models.
- With responsive design, Open WebUI delivers a seamless experience across desktop and mobile devices, catering to users’ preferences and convenience.
- The platform provides hassle-free installation using Docker or Kubernetes, simplifying the setup process for users without extensive technical expertise.
- Seamlessly integrate document interactions into chats with Retrieval Augmented Generation (RAG) support, enhancing the depth and richness of conversations.
- Engage with models through voice interactions, offering users the convenience of talking to AI models directly and streamlining the interaction process.
- Open WebUI supports multimodal interactions, including images, providing users with diverse ways to interact with AI models and enriching the chat experience.
How to Run?
- Clone the Open WebUI repository to your local machine.
git clone https://github.com/open-webui/open-webui.git
- Install dependencies using npm or yarn.
cd open-webui
npm install- Set up environment variables, including Ollama base URL, OpenAI API key, and other configuration options.
cp .env.example .env
nano .env- Use Docker to run Open WebUI with the appropriate configuration options based on your setup (e.g., GPU support, bundled Ollama).
- Access the Open WebUI web interface on your localhost or specified host/port.
- Customize settings, themes, and other preferences according to your needs.
- Start interacting with AI models through the intuitive chat interface.
Using lobe-chat
Lobe Chat is an innovative, open-source UI/Framework designed for ChatGPT and Large Language Models (LLMs). It offers modern design components and tools for Artificial Intelligence Generated Conversations (AIGC), aiming to provide developers and users with a transparent, user-friendly product ecosystem.
Features
- Lobe Chat supports multiple model service providers, offering users a diverse selection of conversation models. Providers include AWS Bedrock, Anthropic (Claude), Google AI (Gemini), Groq, OpenRouter, 01.AI, Together.ai, ChatGLM, Moonshot AI, Minimax, and DeepSeek.
- Users can utilize their own or third-party local models based on Ollama, providing flexibility and customization options.
- Lobe Chat integrates OpenAI’s gpt-4-vision model for visual recognition. Users can upload images into the dialogue box, and the agent can engage in intelligent conversation based on visual content.
- Text-to-Speech (TTS) and Speech-to-Text (STT) technologies enable voice interactions with the conversational agent, enhancing accessibility and user experience.
- Lobe Chat supports text-to-image generation technology, allowing users to create images directly within conversations using AI tools like DALL-E 3, MidJourney, and Pollinations.
- Lobe Chat features a plugin ecosystem for extending core functionality. Plugins can provide real-time information retrieval, news aggregation, document searching, image generation, data acquisition from platforms like Bilibili and Steam, and interaction with third-party services.
How to Run?
- Clone the Lobe Chat repository from GitHub.
- Navigate to the project directory and install dependencies using npm or yarn.
git clone https://github.com/lobehub/lobechat.git
cd lobechat
npm install
- Start the development server to run Lobe Chat locally.
npm start- Access the Lobe Chat web interface on your localhost at the specified port (e.g., http://localhost:3000).
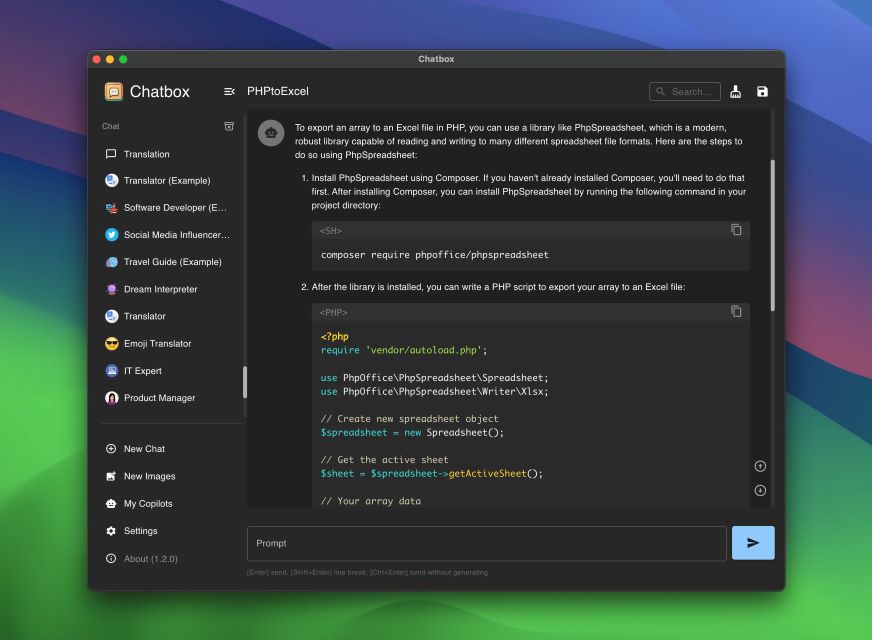
Using chatbox
Chatbox is an innovative AI desktop application designed to provide users with a seamless and intuitive platform for interacting with language models and conducting conversations. Developed initially as a tool for debugging prompts and APIs, Chatbox has evolved into a versatile solution used for various purposes, including daily chatting, professional assistance, and more.
Features
- Ensures data privacy by storing information locally on the user’s device.
- Seamlessly integrates with various language models, offering a diverse range of conversational experiences.
- Enables users to create images within conversations using text-to-image generation capabilities.
- Provides advanced prompting features for refining queries and obtaining more accurate responses.
- Offers a user-friendly interface with a dark theme option for reduced eye strain.
- Accessible on Windows, Mac, Linux, iOS, Android, and via web application, ensuring flexibility and convenience for users.
How to Run?
- Visit the Chatbox repository and download the installation package suitable for your operating system (Windows, Mac, Linux).
- Once the package is downloaded, double-click on it to initiate the installation process.
- Follow the on-screen instructions provided by the installation wizard. This typically involves selecting the installation location and agreeing to the terms and conditions.
- After the installation process is complete, you should see a shortcut icon for Chatbox on your desktop or in your applications menu.
- Double-click on the Chatbox shortcut icon to launch the application.
- Once Chatbox is launched, you can start using it to interact with language models, generate images, and explore its various features.
Conclusion
Running LLMs locally on your computer provides a flexible and accessible means of tapping into the capabilities of advanced language models. By exploring the diverse range of options outlined in this guide, users can find a solution that aligns with their preferences and technical requirements. Whether through web-based interfaces or desktop applications, the ability to deploy LLMs locally empowers individuals to leverage AI technologies for various tasks while ensuring data privacy and control. With these methods at your disposal, you can embark on a journey of seamless interaction with LLMs and unlock new possibilities in natural language processing and generation.

